大家好,我是爱讲故事的某某某。 欢迎来到今天的「五分钟机器学习:进阶篇」机器学习中的Bias-Variance Tradeoff
推荐各位看官在看下面的内容前,先去看下之前的专栏内容「五分钟机器学习:进阶篇」机器学习中的Overfit和Underfit。在理解了什么是Overfit和Underfit之后,回过头来再看今天的内容会有更好的收获。
本期专栏的主要内容如下:
- 什么是Bias和Variance,以及其代表的含义
- 为什么要对Bias和Variance进行平衡(tradeoff)?
什么是Bias和Variance,以及其代表的含义
【这部分数学公式推导不想看的可以跳过,直接记住结论, 误差包含3项,即Bias误差,Variance误差,和随机误差 】
大部分机器学习算法的主要目的,是学到数据中的大致分布(General Pattern),从而将这个分布应用于未知的情况以得到符合规律的结果。而为了衡量一个Supervised Learning算法的训练进度或者这个模型的好坏,比如Linear Regression,我们需要利用Error,也就是样本真实值和模型实际输出值之间的误差。
之前的两期关于Ensemble Learning的视频,我们介绍了Random Forest和Adaboost这两个算法。但是这两个算法由于结构上的不同,导致了极其相异的特性。比如Random Forest模型的起点高,但是天花板低;而Adaboost 性能天花板高,但是起点低。要理解这些,我们需要理解机器学习中的一个基本Concept,也就是Bias-Variance Tradeoff。
所谓Bias偏差,表示的是通过学习拟合出来的分布的期望E[f^(X)],与真实分布之间的差距f(X)。它的数学表达式如下:
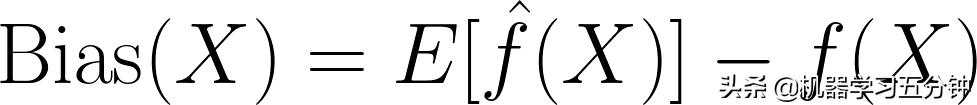
Eq1. Bias 计算公式
所谓Variance方差,表示的是通过学习拟合出来的分布本身的不稳定性。它的数学表达式如下:
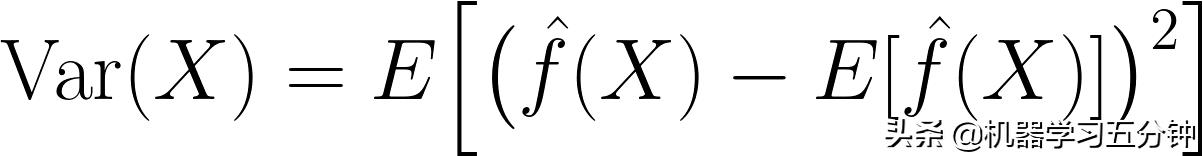
Eq2. Variance 计算公式
那么,如果以一个Regression问题为例,我们做平方差来评估模型性能:
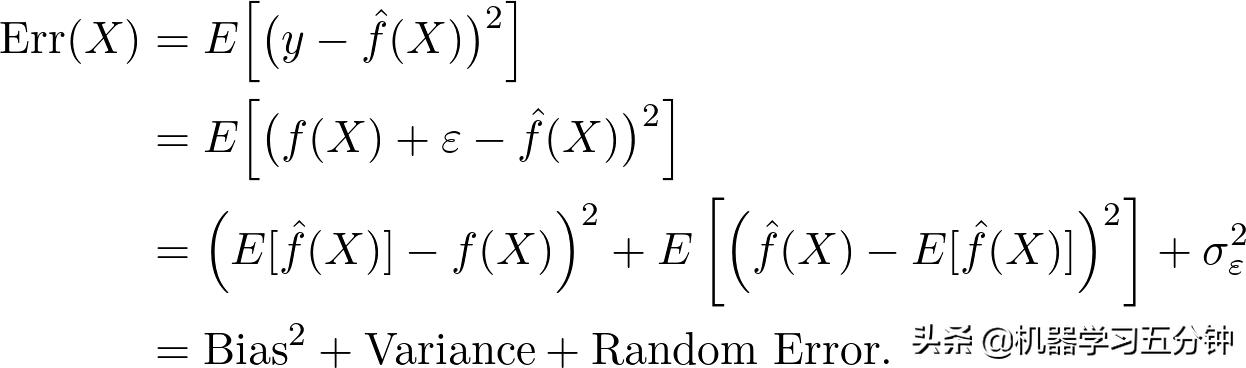
Eq3. 模型误差
可以看到,最终模型的误差包含了三个部分,即Bias平方,Variance,和随机误差(Irreducible Error)。
需要注意的是,在Eq3中的Y表示的是预测值,这是不同于通过学习拟合出来的分布f^(X)。我们一般认为预测值和真实分布之间存在服从高斯分布的随机误差,即:
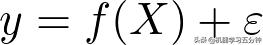
Eq4. 预测值和真实分布之间的关系
那么,为了更好的表示Bias,Variance之间的关联。你可以看下面这张图:
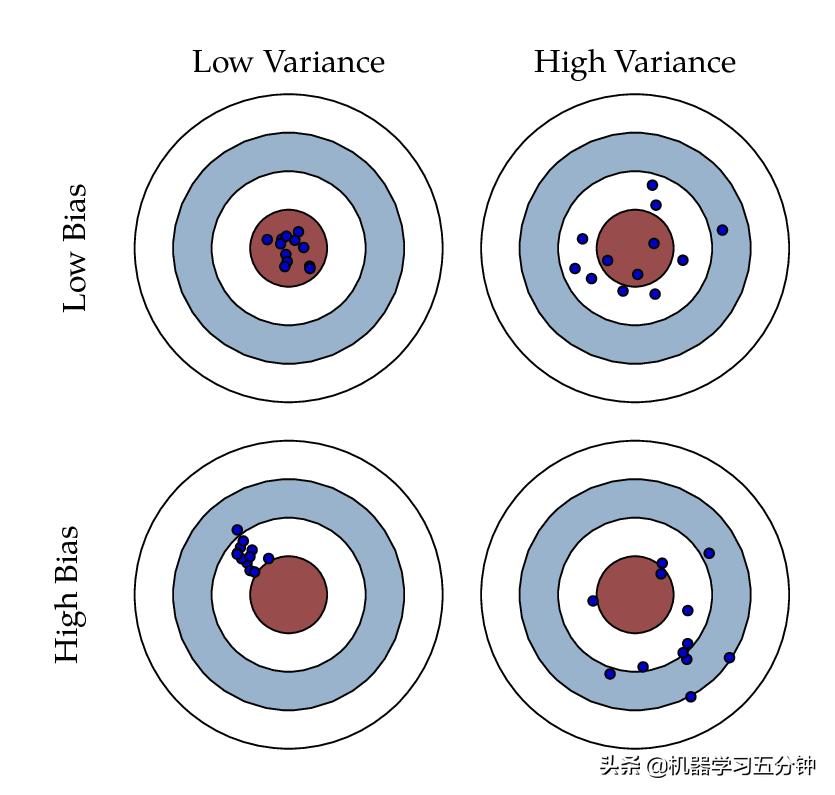
Fig1. Bias and variance using bulls-eye diagram
上图中的靶心代表着我们的学习目标,而蓝点表示的是不同情况下的模型预测输出。可以看到过高的Bias或者过高的Variance都不是好的结果。我们的目标是Bias和Variance都要尽可能的低。Bias低,意味着打的准;Variance低意味着打的稳。
但是在实际情况中,受限于模型的表现力及样本的质量,我们很难达到理想情况,即Bias和Variance都很低。也就是我们会大概率出现High Bias Low Var的情况,Low Bias High Var的情况,或者最糟糕的High Bias High Var的情况。
对于上述中High Bias Low Var的情况,我们可以理解为模型一直很稳定,但是一直不准。联系之前的「五分钟机器学习:进阶篇」机器学习中的Overfit和Underfit,这代表着Underfitting。
相对应的,Low Bias High Var的情况,我们可以理解为模型有时很准,但是非常不稳定。也就是Overfitting。
为什么要对Bias和Variance进行平衡(tradeoff)?
如下图,通常一个模型Variance很高,意味着它往往很复杂,而复杂的模型往往会对某些样本点非常敏感,也就很可能Overfit。同样的,一个模型如果Bias很高,意味着他一直都很不准,所以Underfitting。而我们的目标则是在模型的复杂度之间找到一个平衡,从而使Bias 和Variance都尽可能低,从而得到一个Good Fitting的结果。
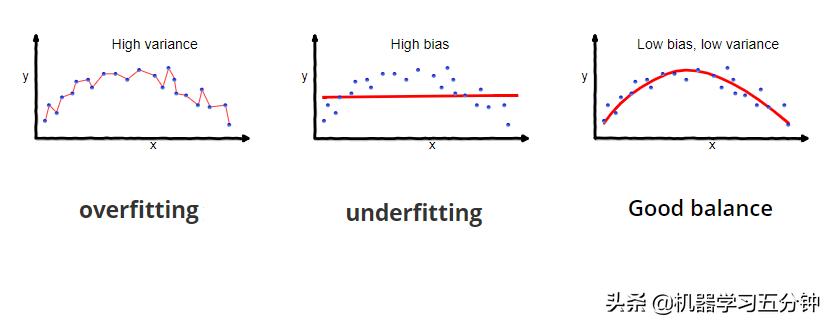
Fig2. Bias-Variance和模型性能的关系
比如,对于同样的数据集,我们训练一个决策树,需要设置树的深度。我们既不能让他太深使令模型太复杂,因为复杂的模型往往意味着不具备Generalization,也就很可能Overfitting;也不能太浅使模型太简单,因为太简单的决策树意味着我们并没有应用足够的条件去划分数据,也就是Underfitting。
通常来说模型复杂度和模型的Error的关系可以用下图表示(对于一个实验,我们专注于找到最小的Total Error 的模型复杂度):
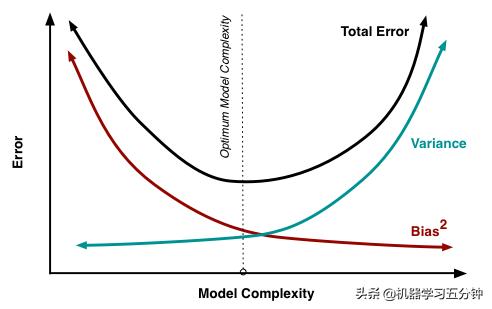
Fig3. 模型复杂度和Error的关系
可以看到,随着模型复杂度的增加,比如更多参数,会使Bias^2降低。直观的理解就是越复杂的模型往往学的会越好。比如你可以对比一下在同一个数据集中运用不同深度的决策树进行学习,更深的树往往上限更高。同时,模型复杂度的增加,也会使Variance升高,也就是不稳定。直观的理解就是,你想得太多,变得畏首畏尾,所以不稳定。
相反的,随着模型复杂度降低,比如更少参数,会使Bias^2升高。直观的理解就是越简单的模型往往学的不如复杂的模型。同时,模型复杂度的降低,也会使Variance降低,也就是变得稳定。比如,一个简单的问题,你往往不需要思考过多,就能很快得出结果。
所以,为了找到这之间的平衡,我们往往需要采用Cross-Validation。也就是,预制很多组超参数的设置(比如训练决策树中的树的深度),然后分别对每组超参数设置进行训练,最后找到那组设置最适合当前的实验。
以上就是今天的【五分钟机器学习:进阶篇】机器学习中的Overfit和Underfit的主要内容了。
如果你觉得本期内容有所帮助,欢迎素质三连。
您的支持将是我继续发电的最大动力~
我是某某某
