#35 RemoteAccessTech-008-WEB资源正向反向代理之争
0、篇首语
近段时间以来,收到反馈想让我讲讲 接入技术 的呼声一直很高,而且确实随着 政策、疫情、攻防演练、业务发展、安全态势 等多方面的影响,企业对于 接入安全 也越来越重视。
而安全业界而言,零信任理念近几年受多方加持越来越火热,不论各家的零信任如何包装粉饰, 接入技术 也是其无论如何也跳脱不开的基本线。
RemoteAccessTech系列不会讨论零信任理念本身,但是会尝试将 远程接入技术 拆开来尽量给大家讲清楚。
1)、RemoteAccessTech-001-从互联网边界接入说起
2)、RemoteAccessTech-002-VPN技术发展史浅析(上)
3)、RemoteAccessTech-002-VPN技术发展史浅析(下)
4)、RemoteAccessTech-003-理解隧道协议
5)、RemoteAccessTech-004-SDP也是一种SSL VPN?
6)、RemoteAccessTech-005-VPN隧道技术的核心流程
7)、RemoteAccessTech-006-WEB资源-典型Layer7 VPN
8)、RemoteAccessTech-007-WEB资源-非标web站点的适配困境
1、从正向(转发)代理开始
在 RemoteAccessTech-002-VPN技术发展史浅析(下) 中我们提到,SSL VPN早期就是WEB资源起步。
那么最初的WEB资源其实更多是 正向代理(转发代理,Forward Proxy)技术思路 的延展。
其最初技术思路来源,和 online web proxy是一致的,如下图中的 proxyium。
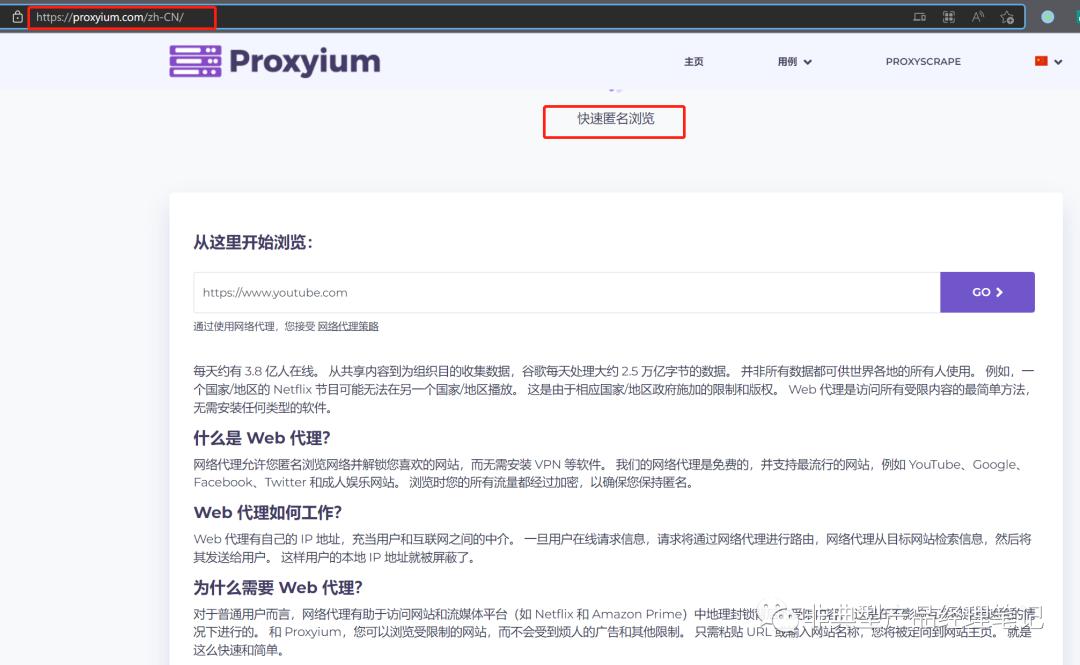
online web proxy 最初是为了代理上网(或匿名上网),所以具备如下关键的特征:
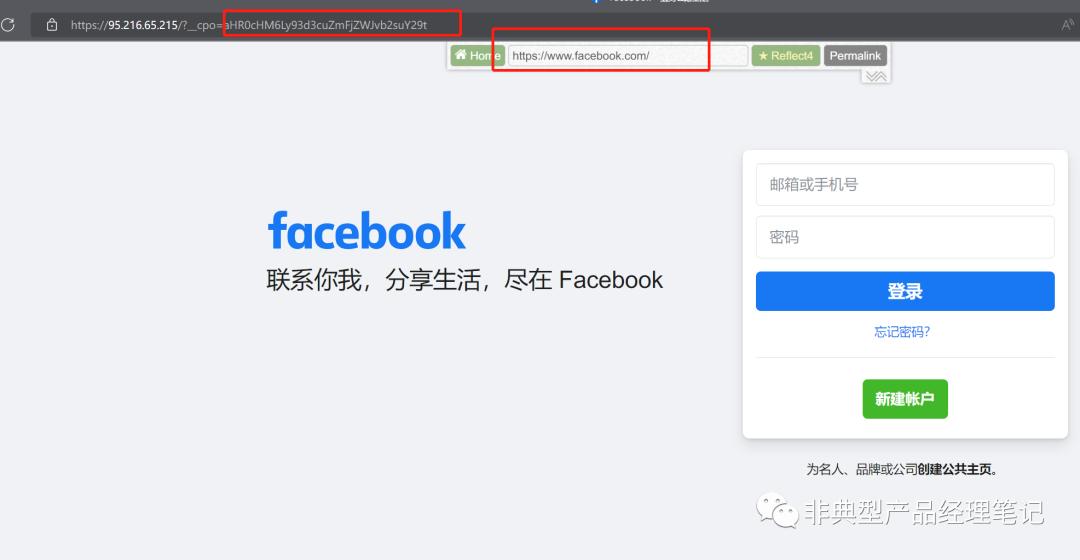
1)、 一个互联网入口 ,即可 代理访问多个不同的目标业务 。如下gif图,hosteagle.club域名中,就代理访问了 facebook、google两个业务。
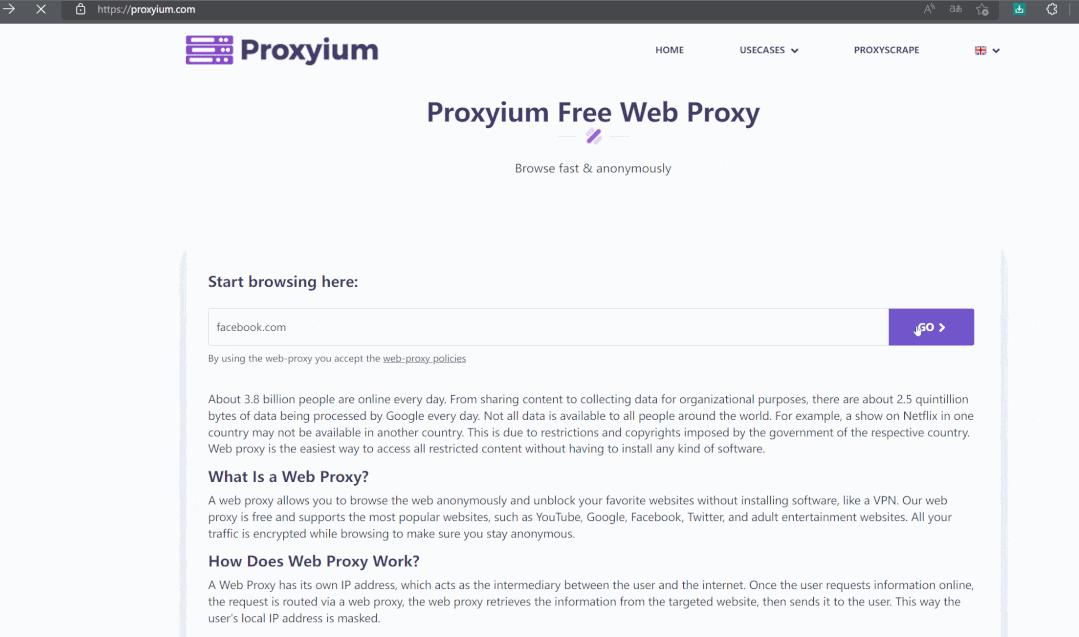
2)、 不依赖于公网域名 :如下gif图, croxyproxy 是使用IP提供的访问代理服务,也可以正常实现访问代理。

而恰好,早期SSL VPN的WEB资源,也需要符合这两个约束:
1)、早期不少客户可能只有IP没有域名,需要 减少对域名的强依赖
2)、早期不少客户可能只有一个IP或一个域名( 甚至只有一个端口 ),需要能通过 一个入口代理访问多个目标业务系统
1.1、 online web proxy的机制参考
基于正向代理 的WEB资源,最核心需要解决的问题,是一个 公共入口下,如何区分目标业务系统 。
考虑到 online web proxy和 SSL VPN的正向WEB资源的区别,主要是是否有认证的区别。所以这里简单看几个online web proxy(免认证) 的方案机制。
1.1.1、croxyproxy方案
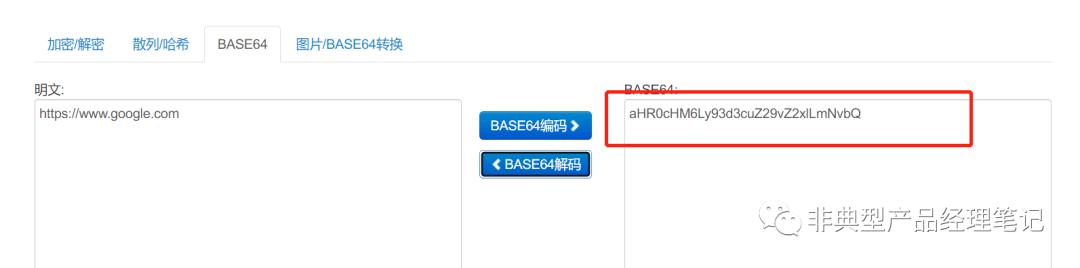
原始URL (目标URL): https://www.google.com/search?q=searchme
引流URL (浏览器代理访问的URL): https://95.216.65.215/search?q=searchme&__cpo=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbQ
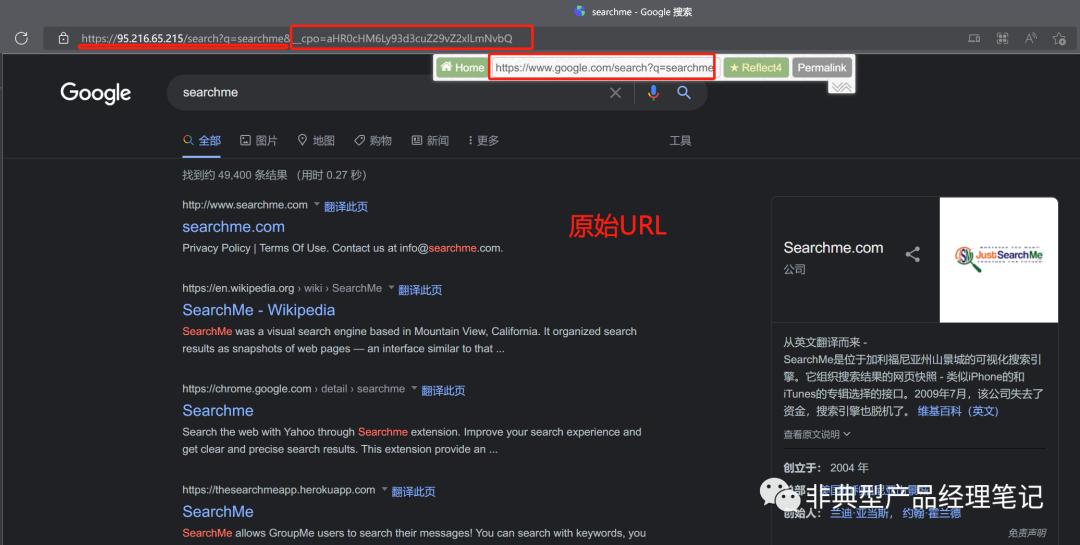
在 RemoteAccessTech-007-WEB资源-非标web站点的适配困境 中第 3.1、WEB资源的引流依赖 中,我们提到,完整的URL至少有:Schema、Domain、Port、Path四个部分。
通过对 __cpo参数进行BASE64解码,发现解出来正是 https://www.google.com ,此参数包含了Schema、Domain、Port三部分。
而Path和参数, /search?q=searchme 则直接带在了https://95.216.65.215之后。
基于此规则,我们也可以自己编码一个新的站点,如下:

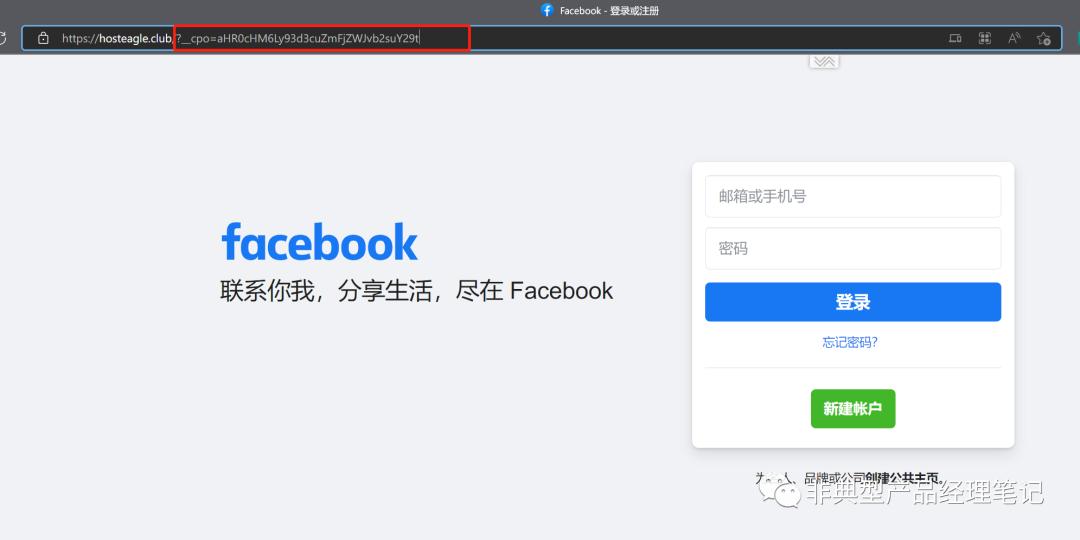
1.1.2、proxyium
这个厂商很可能方案和croxyproxy是一致的,因为连参数机制都是相同的, __cpo=BASE64(URL)。
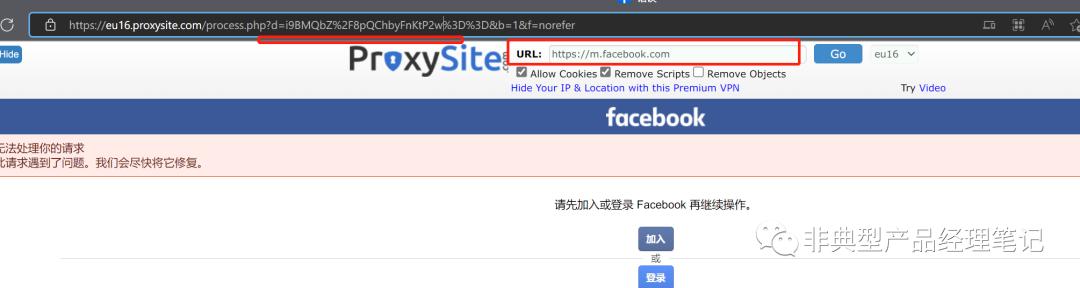
1.1.3、proxysite
同样是通过 参数传递域名 。
1.2、正向WEB资源区分目标业务系统的典型模式
简单列举一下区分目标业务系统的主要机制 :
1)、 【主流方案】基于参数区分 :比如说 https://125.93.20.90/?__origin=BASE64(源站地址) 。类似于上面Proxyium所使用的机制
2)、【补充方案】基于端口区分 :比如说 125.93.20.90:8080 代表 OA系统;125.93.20.90:8081 代表 百度; 125.93.20.90 代表 172.16.1.101:80
3)、【不可行】基于域名区分 :比如说 oa.vpn.com 代表 OA系统, baidu.vpn.com 代表百度, 172-16-1-101.vpn.com 代表访问 172.16.1.101:80 。
基于域名区分的方案,在 正向代理时代 是不可行的,因为 违背了不依赖域名、IP也可用的约束 。 注:当然我们后面会发现,在反向代理为基础的时代,依赖域名反而变成了可行的。
2、正向代理模式下的兼容性模型
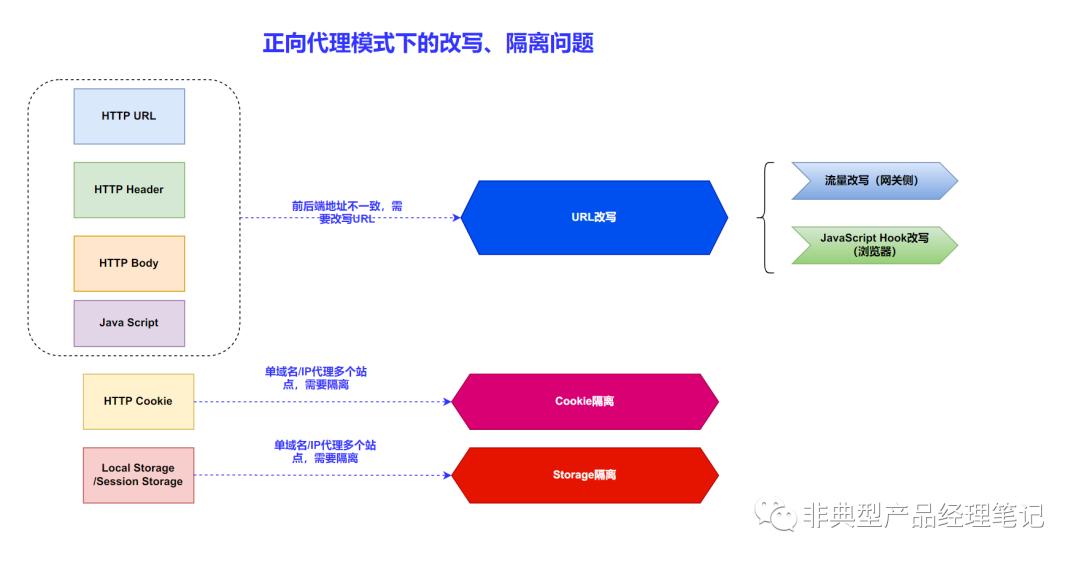
2.1、URL改写
URL绝对路径,有可能出现HTTP Content(如html中静态写死),也可能出现在HTTP API请求的Request body或Response Body中。
同时,也还可能在javascript的JS代码中静态硬编码写死,也有可能在javascript中动态拼接调用。
所以如果要较为完备地处理,需要在流量侧、浏览器侧都进行URL改写。
1)、 流量改写(网关侧) :
早期的 web proxy优先只处理流量,最典型的模式的就是通过对http body(包含Request、response)、header等进行 正则匹配替换 。
比如说 源站地址是 http://172.16.1.101:8080 , 前端地址是 https://oa.company.com。那么就需要针对:172.16.1.101:8080、http://172.16.1.101:8080、//172.16.1.101:8080 (上为绝对路径的多种不同写法)进行相应替换。
流量改写 ,可以解决HTML、API的Request/Response Body、Javascript中硬编码写死的URL地址修正的问题。
不能解决的问题 :对于有对地址进行了编码(如base64)或加密的数据,无法通过识别并正则修正。
2)、脚本改写(浏览器侧):
我们在 RemoteAccessTech-007-WEB资源-非标web站点的适配困境 和 3.5、业务系统不规范典型举例 中提过几种不规范的使用方式,其中第3条则是典型的通过浏览器侧运行的脚本进行的运行时修改,这部分在流量中是无法看到的,代理网关自然无从介入。
3、更厉害的是前端JS逻辑中拼装绝对路径:比如说某个用户的一个业务,一共有3个后端服务器,IP地址分别是 172.16.0.1、172.16.0.2、172.16.0.3。然后开发人员在写业务代码时,用一个随机数去随机 1-3这个数字,再拼接上前缀 172.16.0 ,从而拼成完整的IP地址,再调用 http://172.16.0.1/xxxx 的接口。这种方式在IP升级域名、域名变更等场景下,都需要重新修改代码。
包括使用javascript去拼接路径, document.write('<a href=http://' + site +'/news.html> 新闻 </a>') 。
浏览器JS脚本,对路径的生成、拼接是非常灵活的,如果想在生成或拼接环节进行处理,几乎是太可能。那么可以在哪些环节进行处理呢?
答案是在其获取(输入)、消费(输出) 的环节进行处理。
2.1)、 获取domain/URL的环节(输入): 比如说部分网站可能会在前端JS中,通过 document.domain 接口获取当前站点的domain,以避免自身处于沙箱环境。
2.2)、跳转URL(输出):如 windows.location、document.location、location、windows.open ,类似于 location.href="http://xxx.com" ,需要对跳转环节进行拦截处理,避免发生逃逸。
2.3)、AJAX调用(输出): Asynchronous JavaScript + XML(异步 JavaScript 和 XML,AJAX) 是一种浏览器前端和后端接口通信的机制,JS中可以通过ajax接口调用服务端API接口。
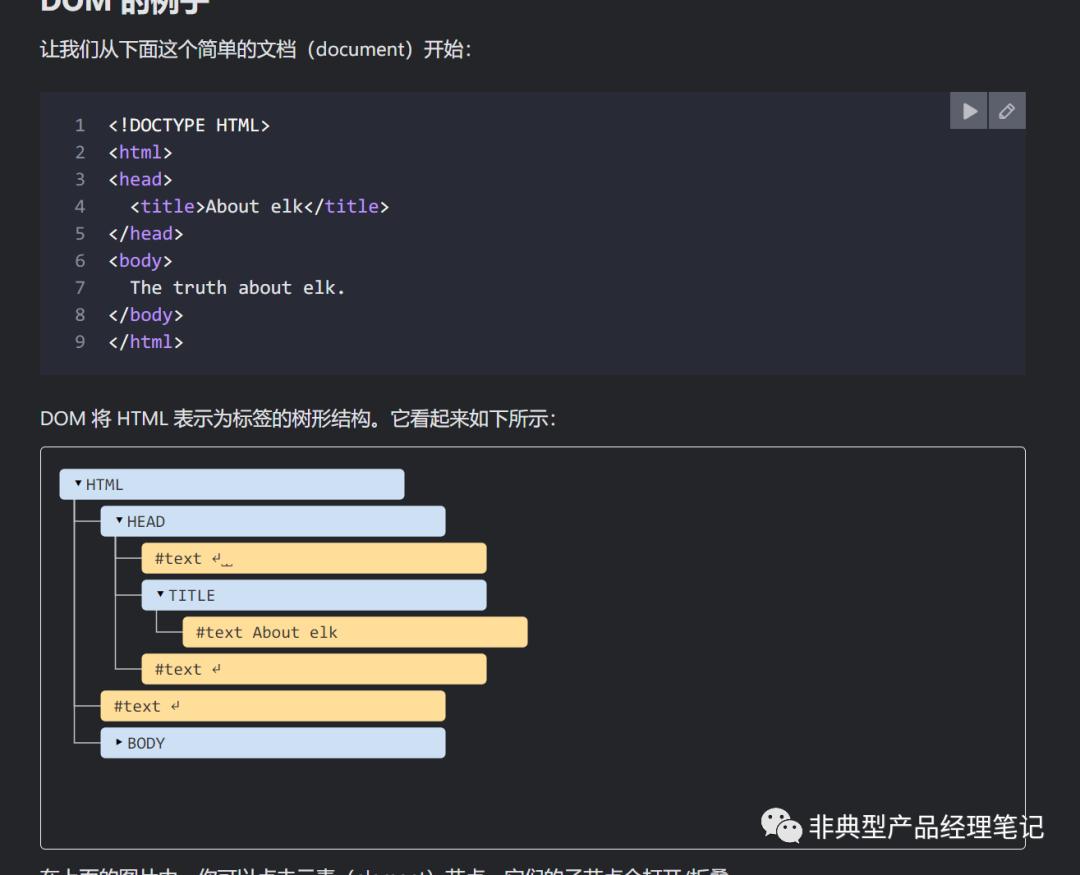
2.4)、修改DOM内容(输出):DOM(Document Object Model,文档对象模型) 是一种可以用于获取和修改HTML内容的机制,比如说通过document.getElementById(id)、element.innerHTML 等一系列API,进行相关修改操作,可以将其中涉及到的绝对URL,修改为相对URL。
DOM介绍可参考 https://developer.mozilla.org/zh-CN/docs/Web/API/Document_Object_Model/Introduction
另一个DOM内容示例(https://zh.javascript.info/dom-nodes):
2.2、Cookie隔离
2.2.1、什么是Cookie
可参考 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Cookies
HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态 。Cookie 使基于无状态的 HTTP 协议记录稳定的状态信息成为了可能。
Cookie 主要用于以下三个方面:
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
个性化设置(如用户自定义设置、主题等)
浏览器行为跟踪(如跟踪分析用户行为等)
上我们在 Auth-Learning-005-零信任SDP和4A对接认证&SSO(PC端) 的第4.2.4章节 HTTPS-Cookie共域方案中有过Cookie效果解读,如下:
在WEB站点中,一直以为Cookie都扮演了一个很重要的角色 — 会话保持。怎么理解呢?
回想一个场景,当用户访问一个web站点时,只在登录页面输入过一次用户名密码,后续再访问其他页面,就不需要再输入用户名密码了。
那么,这里是需要有一种方式去保存用户凭证(token)的,这个凭证的保存方式,占比最广的就是Cookie。
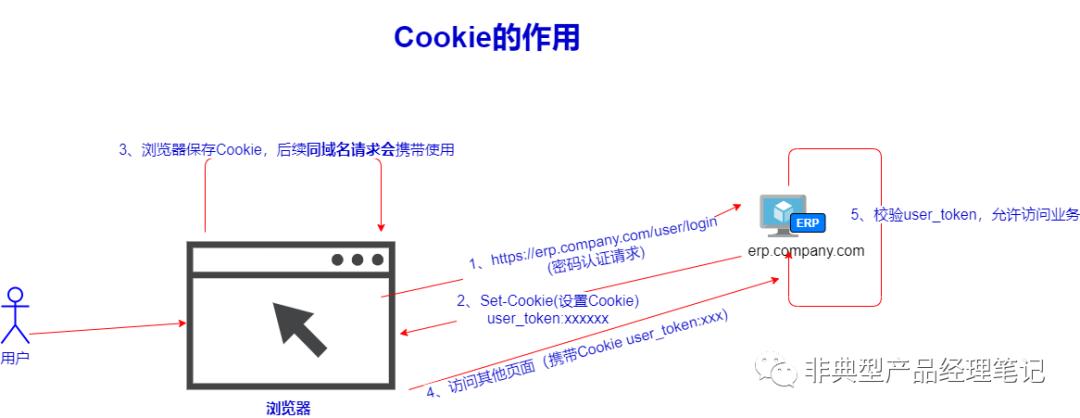
根据上述流程,可以看出Cookie的作用,很重要的点是由浏览器进行保持,携带给服务端,以便服务端验证会话信息的一种方式。
1、用户通过浏览器 发起密码认证请求
2、密码认证通过后,服务器下发Set-Cookie指令,要求浏览器保存user_token的Cookie键值
3、浏览器将Cookie保存到该域名下,后续同域名请求会自动携带相关Cookie
4、用户访问该站点其他页面时,会自动携带Cookie。其中包含了user_token
5、服务器校验user_token,根据权限允许访问业务
从上述也可以看到Cookie的重要性,对于多数业务型站点,Cookie都是不可或缺的机制。
2.2.2、Cookie冲突与隔离
由于多个站点(不同域名)之间,Cookie是隔离的,所以多个业务在使用Cookie时,就很有可能会有相同的命名。比如都叫session 、sid、t等。
此时,如果不作特殊的处理, 单域名/IP的代理机制下 ,同名Cookie就会导致Cookie冲突。
那么一般的方式,是采用后缀进行隔离。如下图:
1)、sb@facebook.com 表示 源站facebook.com 下的sb Cookie。
2)、NID@google.com 表示 源站google.com 下的 NID Cookie。
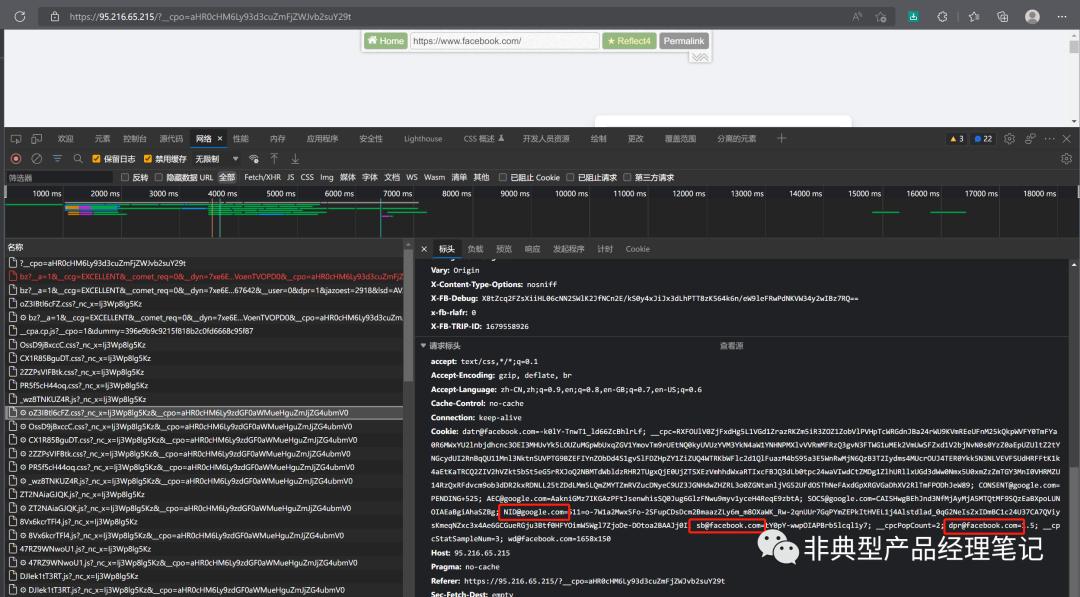
代理网关向源站发起请求时,根据后缀进行处理,进行还原即可。如下图:
1)、 前端Cookie dpr@facebook.com 映射至 facebook.com源站访问时的 Cookie dpr
2)、前端Cookie sb@facebook.com 映射至 facebook.com源站访问时的 Cookie sb
3)、 前端Cookie NID@google.com 映射至 google.com源站访问时的 Cookie NID
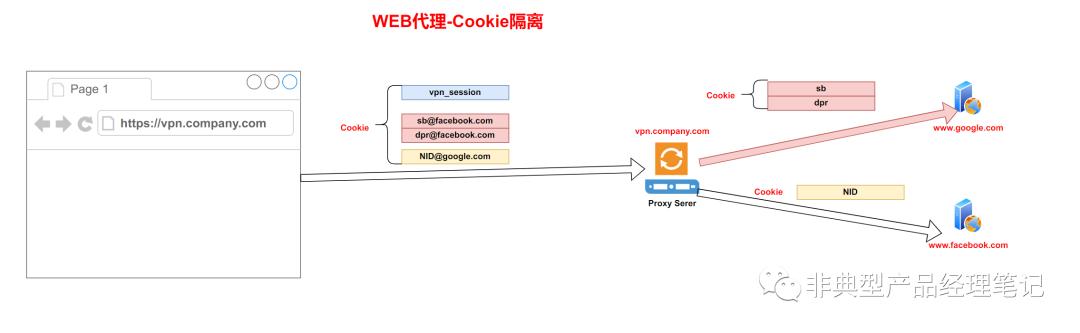
2.2.3、单站点Cookie隔离的遗留问题-Cookie数量超限
但是很不幸,即使做了Cookie隔离,仍然会遇到Cookie数量上限问题 。
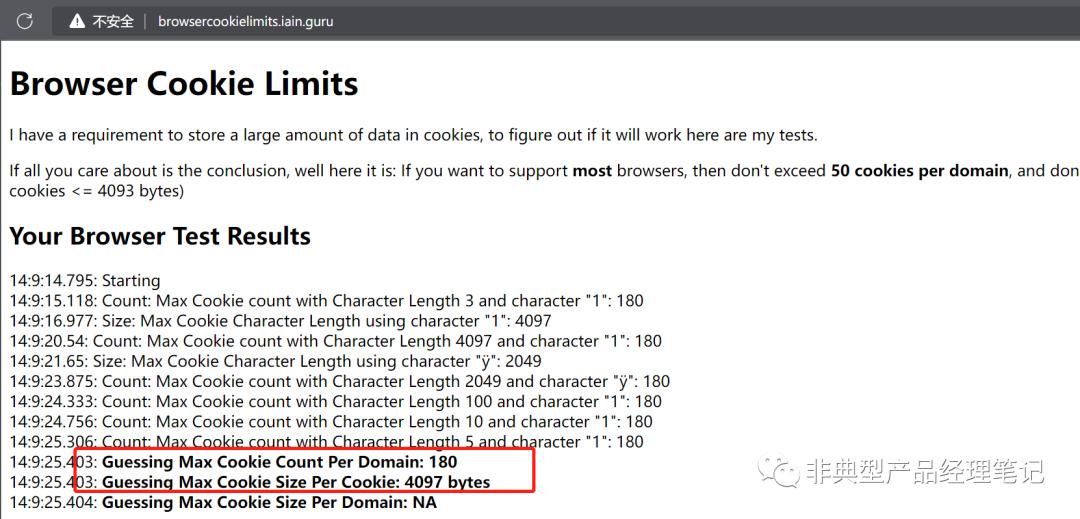
原因是每个单一域名下( 如vpn.company.com ),浏览器所支持的Cookie数量是有限的,通常可能在20个-180个类似的区间内。比如说IE8及以上,是50个Cookie;Chrome上限是180个;Firefox是150个。
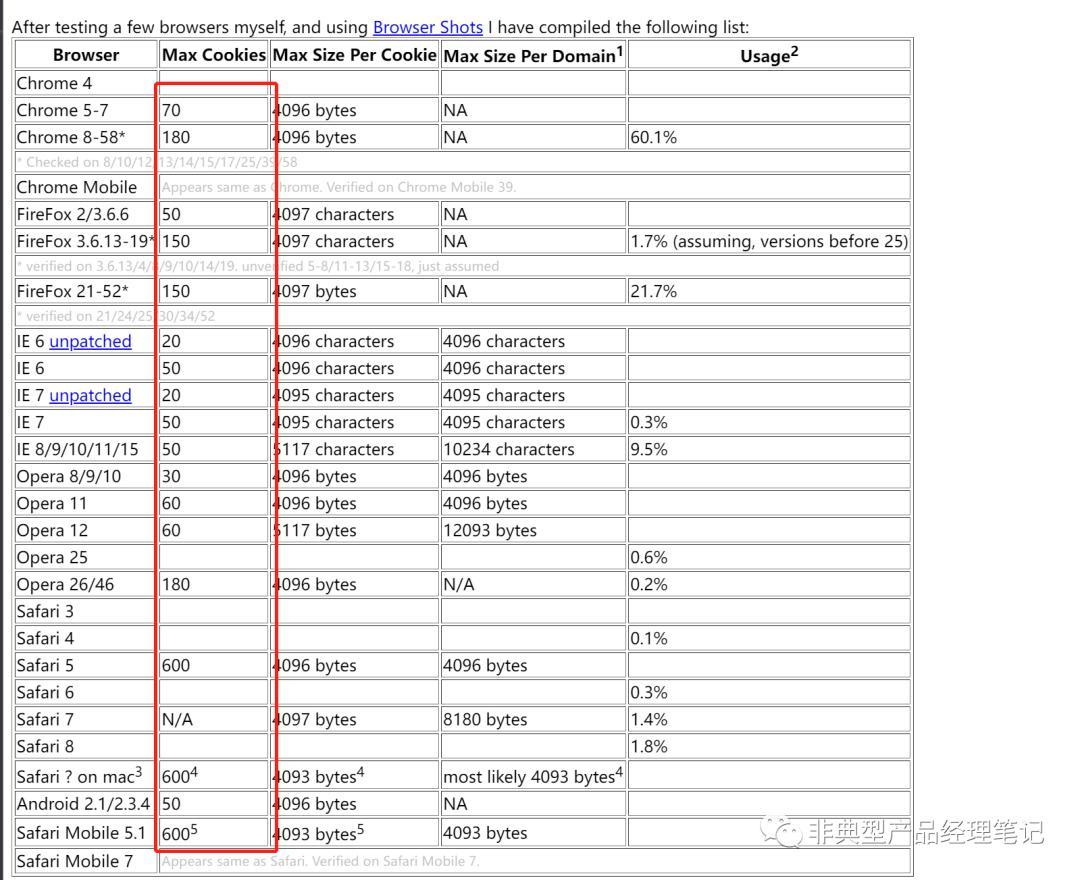
在该情况下,如果WEB代理了多个真实域名,就会遇到Cookie超限的情况。
通过 http://browsercookielimits.iain.guru/ 站点,可以对浏览器支持多少个Cookie进行测试。如下红框按钮:
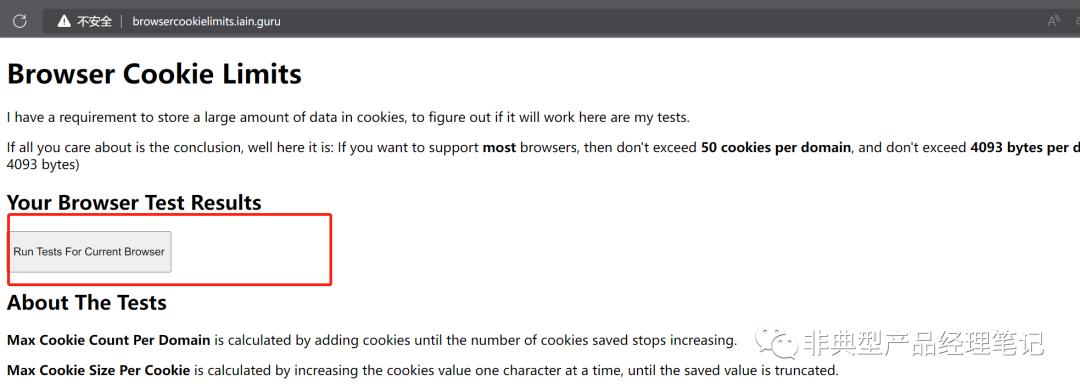
下面是我在Microsoft Edge上的测试结果,如下:
2.2.4、端口映射能缓解Cookie数量超限问题吗?
此时就有人问,那我能通过端口映射,多个端口(如8080、8081等)来避免Cookie超限问题吗?
很不幸,并不能。基于 RFC 6265 ,对此问题进行了描述:
Similarly, cookies for a given host are shared across all the ports on that host, even though the usual "same-origin policy" used by web browsers isolates content retrieved via different ports.
以及:
8.5. Weak ConfidentialityCookies do not provide isolation by port. If a cookie is readable by a service running on one port, the cookie is also readable by a service running on another port of the same server.
显而易见,Cookie是并不区分端口的。所以 端口映射不能解决Cookie数量超限问题 。
3、反向代理模式的WEB资源
3.1、WEB资源-反向代理模式关键变化
很显然,正向代理的单站模式,是有其历史因素在内的。
近几年包含WEB资源的SDP产品,默认都采用了反向代理的机制去实现。
切换为反向代理后,最大的差异是采取多域名方案,实现一站一域名。同时,反向代理机制,默认认为业务系统是规范的,故不少厂商实现默认不提供URL改写相关能力。
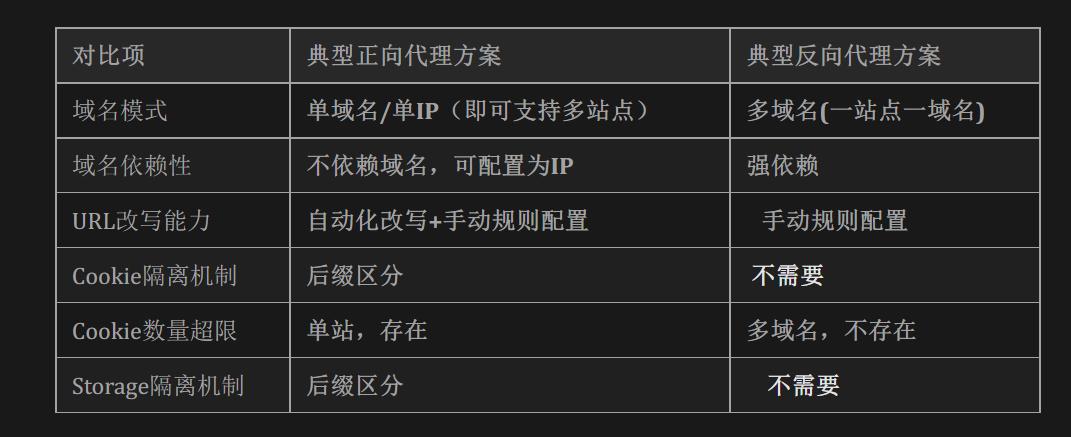
可以看到反向代理之后,带来了几个关键变化:
1)、 多域名方案下,前后端1:1映射,额外的Cookie和Storage隔离机制不再需要。相对应的比如说Cookie数量超限不再存在。
2)、URL改写简化:默认要求前后端地址一致或业务规范化,从而避免URL改写。
3.2、反向代理型WEB资源的能力增强
反向代理方案 在实际落地时,虽然对Cookie/Storage隔离的依赖减弱了,但是考虑到仍存在业务不规范的场景,所以主要在URL改写能力上仍会体现出差异。
这里针对主站URL和依赖站点的URL改写会有所不同,后者比前者要复杂。
1)、主站URL:用户直接感知,有可能会输入其地址进行访问的,被认为是主站,如 oa.company.com 即是主站点。管理员需要为主站分配权限,如基于RBAC的静态授权
2)、依赖站点:比如说 oa.company.com 中,涉及到图片缓存 img.company.com 或 video.company.com 等此类后台资源型站点,主站点需要依赖于这些站点才能工作,依赖站点的权限跟随主站。
值得注意的是,一般越是不规范的业务系统场景,其依赖站点越不可控。反而是规范的业务系统,其依赖站点是可以很容易梳理出来并进行快速配置的。

3.3、反向代理型WEB资源的典型技术方案
反向代理型WEB资源,通常会选择主要的中间件,如apache、nginx,以后者居多。
比如说 Openresty(nginx+luajit) 就是一个可行的基座选择( https://openresty.org/cn/ )。
OpenResty® 是一个基于 Nginx[1] 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和*态网动**关。
OpenResty® 通过汇聚各种设计精良的 Nginx[2] 模块(主要由 OpenResty 团队自主开发),从而将 Nginx[3] 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx[4] 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
OpenResty® 的目标是让你的Web服务直接跑在 Nginx[5] 服务内部,充分利用 Nginx[6] 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
apache apisix 是另一套可选的基于 nginx+lua 技术栈进行实现的API网关,同样可用于实现反向代理型WEB资源( https://apisix.apache.org/zh/blog/2021/08/25/why-apache-apisix-chose-nginx-and-lua/ )。
3.3.1、自研中间件 VS 主流开源中间件(如nginx)
反向代理的中间件选择上,通常来说,有自研和主流开源两种模式。
总体而言,如果安全公司在基础设施上投资不足的情况下,建议采用主流开源,其从安全、兼容性视角均更为可控。
从实际角度 ,国内绝绝大多数安全公司,在基础设施上都不足以支撑一套安全、高性能、兼容完备的代理中间件实现。
这有点类似于浏览器(当然没有浏览器这么大投入),据不权威测算,浏览器内核google公司投入了上千亿计的美金投入用于构建Chromium浏览器,最终形成事实标准,连Microsoft也在EDGE浏览器中采纳其浏览器内核。
而关于自研中间件其安全性,可以参考HVV专题,如 HVV-Learning-006-应用安全和理解安全漏洞
以及参考 HVV-Learning-010-边界突破-浅谈对外暴露的安全设备&应用安全 中 第3.1章节:
我们首先都知道,应用/业务系统是随着业务系统频繁变化的,可能一个复杂些的业务系统就有10个模块,每个模块100个接口,一共1000个以上的API接口,每个接口可能平均又有200行代码,共计20万行代码。简单一些的业务系统,业务代码可能在几万行代码左右。
总体而言:
1)、从概率上而言,只要是人写的代码,漏洞难以避免。
2)、如果没有完备的SDL机制和安全投入,其漏洞数量,会和代码行数成正比,而且漏洞数量很可观。
如确实涉及自研代理架构,建议需要参考如下几个标准进行甄别:
1)、【架构安全】最好是近5年重构的安全架构。如果很古老(比如说10年+),大概率是没有底层安全设计的。
2)、【语言安全】建议选择rust、golang此类内存安全的语言开发。
3)、【流程安全】需要有完备的SDL机制流程和足够的投入
4)、【业务连续性】建议有较大规模的产品运用和交付,以避免在可靠性和兼容性上存在明显缺失
综上, 自研代理中间件在绝大多数情况下,其安全风险会高于主流开源(如nginx) ,在选择时需要严谨看待。 更不用说其在代理协议的兼容适配上,更是可能会拉开数以十倍的差异(如果兼容特性缺失,可能会引发一些站点访问不正常) 。
参考资料
[1]
Nginx: https://openresty.org/cn/nginx.html