线 下实体商店、餐饮店或糕点店等面临着规模较小、产品种类繁多以及线上购物的竞争等挑战。利用AI人工智能进行销量预测可以帮助它们更好地应对这些挑战,减少浪费,降低成本,提高效率。具体而言,销量预测在以下方面具有重要意义:
a. 库存管理和采购计划:准确的销量预测可以帮助商店合理规划库存水平,并优化原材料采购计划。通过避免过多采购,可以降低库存成本和存储成本,并减少因积压商品而导致的浪费。
b. 营销和促销策略:销量预测可以为商店制定更精准的营销和促销策略提供依据。根据预测结果,商店可以针对不同产品制定定价、促销活动或优惠策略,以提高销售额和顾客满意度。
c. 供应链优化:通过准确的销量预测,商店可以与供应链合作伙伴共享信息,共同优化供应链的运作。合理的店间调拨和流通安排可以减少调拨成本,确保库存的及时补充,降低缺货风险。
d. 避免折价销售和降低风险:精确的销量预测可以帮助商店避免过量采购和库存积压,减少因折价销售而造成的损失。此外,预测模型还可以帮助商店降低食品安全风险,及时处理过期或易腐烂的商品,确保产品的品质和安全。

利用高精度、高稳定性的销量预测模型可以帮助线下实体商店、餐饮店或糕点店等合理规划采购和库存,减少浪费和成本,并降低缺货和折价销售的风险。这样不仅可以提高经营效率和利润,还可以提供更好的客户体验,增强竞争力。
销量预测的基本步骤
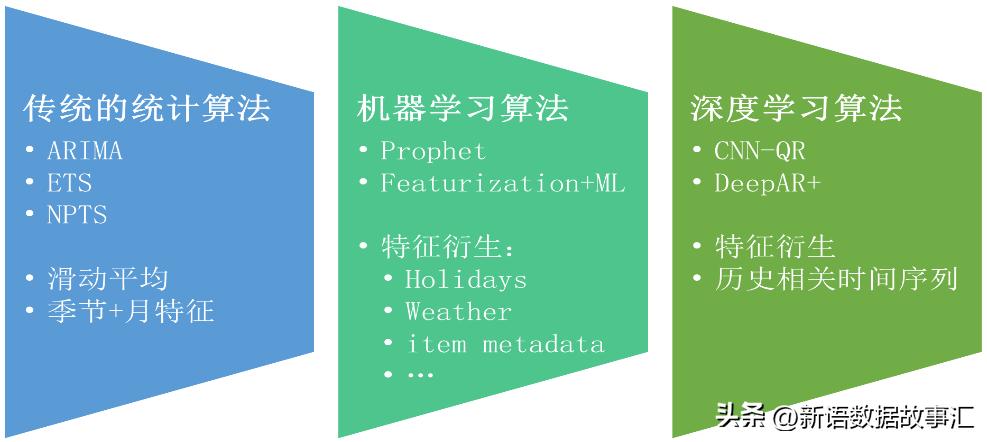
销量预测本质上是时间序列预测的一种应用;销售数据通常按时间顺序排列,形成一个时间序列,通过分析和建模这个时间序列,可以预测未来销量的变化趋势。因此,销量预测可以看作是时间序列预测的一种特定应用。传统的时间序列预测模型包括移动平均法(MA)、指数平滑法、自回归移动平均模型(ARMA)、季节性自回归移动平均模型(SARMA)、自回归整合移动平均模型(ARIMA)、季节性自回归整合移动平均模型(SARIMA)等在预测宏观整体走势上有比较好的效果。但是在应对单品(SKU)在一个便利店上销量预测是无法应对的,还是要使用机器学习方式类预测,尽量寻找尽量多的特征(影响因素)比如:天气、节假日、营销活动、或其他社会突发活动及市政活动等。当前也有衍生深度学习的算法来销量预测。下图销量预测的相关方法不完整列表。
机器学习方式进行时间序列预测或销量预测,实际上是将时间序列进行空间转换、并泛化特征进行训练学习形成模型进行预测。时间序列与机器学习的转化关系参照下图:

销量预测是一个复杂的任务,通常涉及数据探索分析(EDA)、特征挖掘、模型构建和评估等步骤。
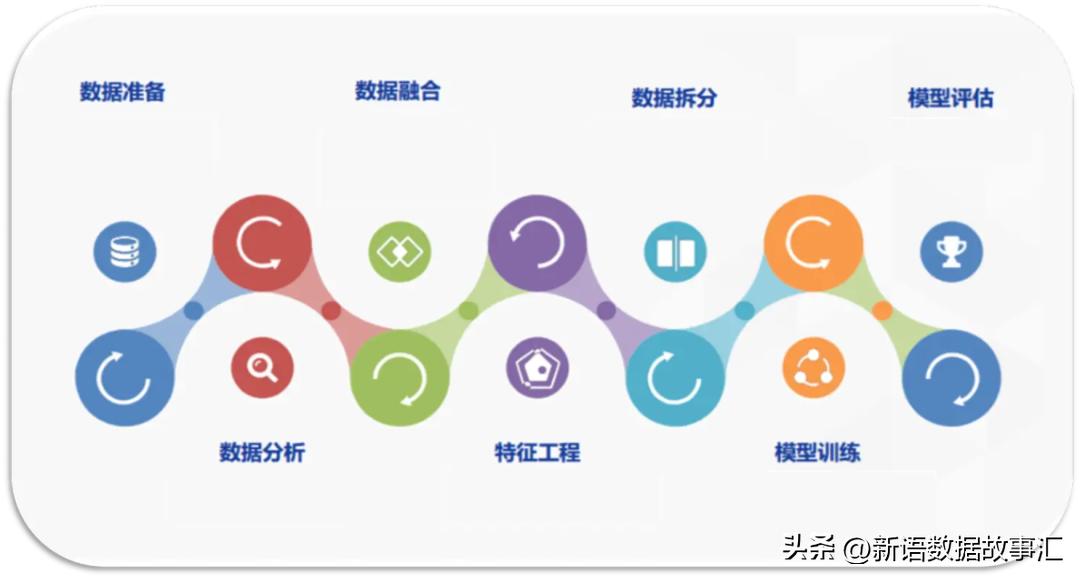
在销量预测中,数据探索分析(EDA)是首要步骤。通过对数据集进行统计分析和可视化,我们可以了解数据的分布、趋势和相关性等信息。
接下来,特征挖掘是为了从数据中提取有用的特征。这可能涉及选择与销量相关的特征、进行特征工程和转换,以及创建新的特征变量。常见的特征包括时间相关特征、促销活动、季节性因素和产品属性等。
在特征准备好后,我们可以构建销量预测模型。常用的模型包括线性回归、决策树、随机森林、支持向量机和神经网络等。根据数据集的特点和需求,选择适当的模型并进行训练。
最后,对于训练好的模型,需要进行评估以衡量其性能。常用的评估指标包括均方根误差(RMSE)、平均绝对百分比误差(MAPE)、R平方等。这些指标可以帮助评估模型的准确度和预测能力。
实际项目中可能会涉及到更多复杂的因素和技术,以及实际数据的处理和模型调优等。确保在项目中遵守数据保密和隐私政策,以保护敏感信息的安全。
数据集介绍
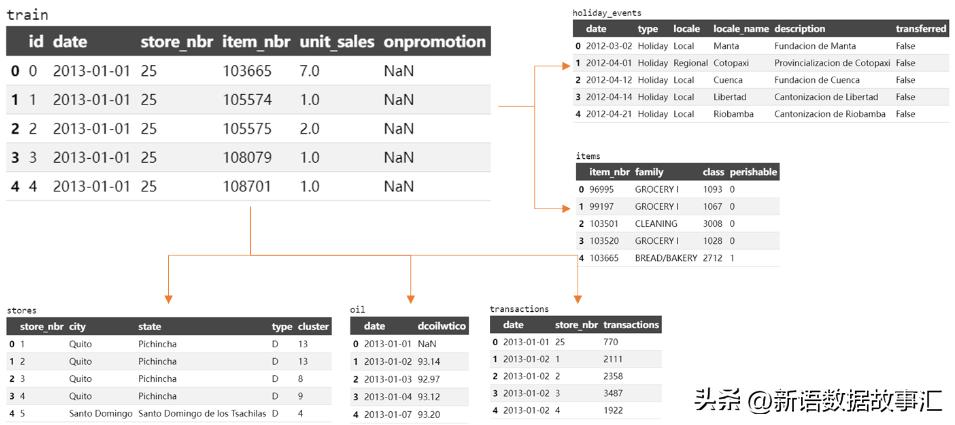
数据集引用Kaggle 上一个竞赛数据集(https://www.kaggle.com/competitions/favorita-grocery-sales-forecasting/data),数据集是厄瓜多尔 Favorita 商店销售的数千件商品的销售额流水数据。训练数据包括日期、商店和商品信息、该商品是否正在促销以及单位销售额。数据集如下:
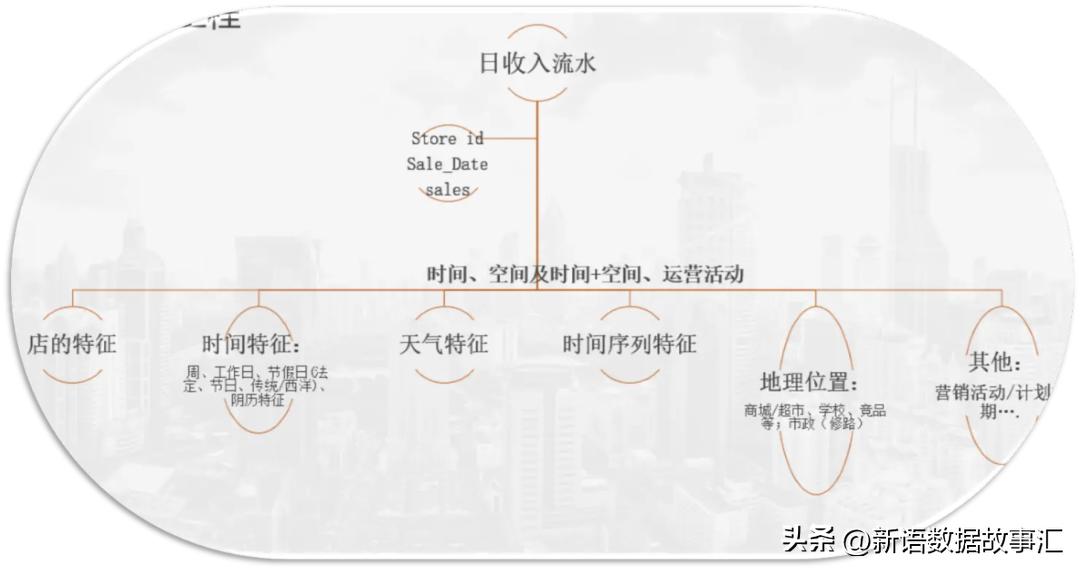
- train 是训练数据,主要数据集,字段包括日期、商店编号、商品ID、销售单位(unit_sales、可以是整数例如:一袋薯片或浮点数例如,1.5 千克奶酪)、onpromotion列说明该商店item_nbr是否针对指定的date和进行了促销活动。
- stores:商店的特征数据,包括所在城市、州、类型、聚类(cluster是一组类似的商店)。
- items:商品item数据,包括:包括family、class和perishable。注:标记为的项目的perishable得分权重为1.25;否则,权重为1.0。
- holidays_events:假期和活动数据。
- oil:油价数据,每日油价,厄瓜多尔是一个依赖石油的国家,其经济健康状况极易受到油价冲击的影响。
- transactions:date每个组合的销售交易计数store_nbr。仅包含在训练数据时间范围内。
数据探索分析(EDA)
SmartNoteBook 内置EDA(Exploratory Data Analysis)探索组件和可视化分析组件:
- EDA分析组件(单元格)是一种同时交互式探索大量数据点的工具。提供了一个交互式界面,用于探索数据集所有不同特征的数据点之间的关系。可视化中的每个单独项目表示一个数据点。通过按特征值在多个维度上对项目进行“镶嵌”来定位项目。EDA分析组件的成功案例包括检测分类器故障、评估基本事实和潜在的新特征信号。
- 可视化分析组件(单元格)是一种无需编写代码以交互的方式探索、分析和可视化数据的单元格组件,可以创建丰富的图表用于展示和分享。
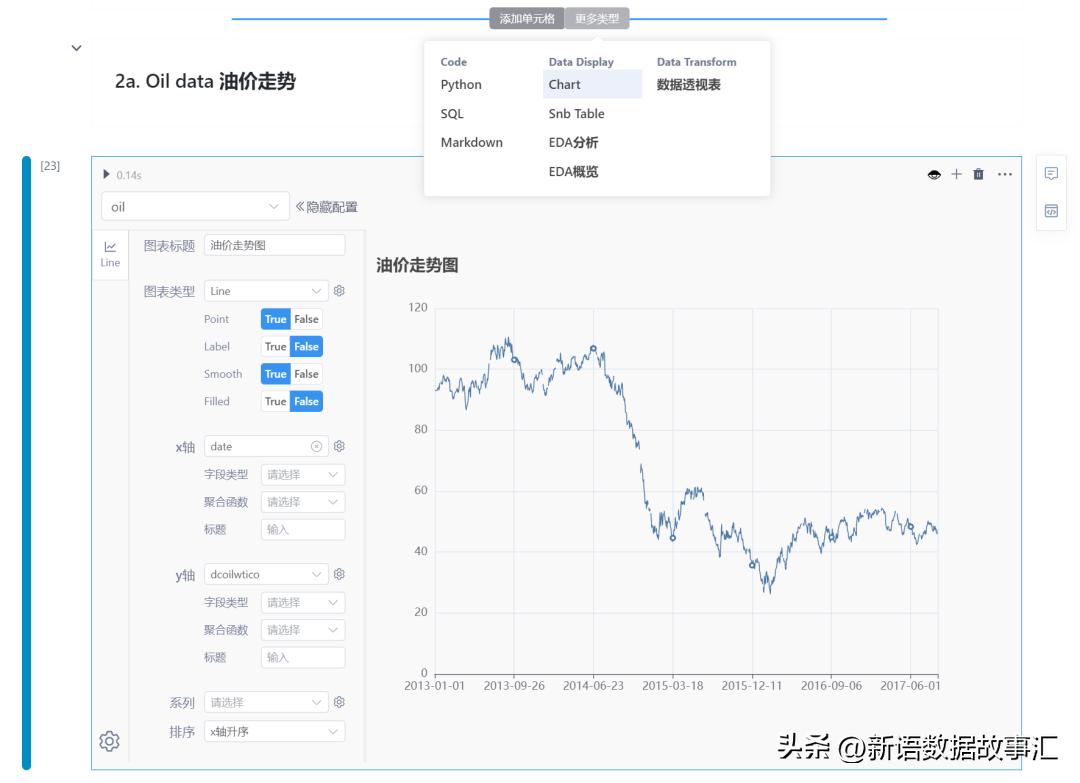
Oil 油价走势
- 插入chart 单元格,选取oil 数据集(df)
- 图表类型选为:Line,设置x轴、y轴的数据列,然后运行生成图表
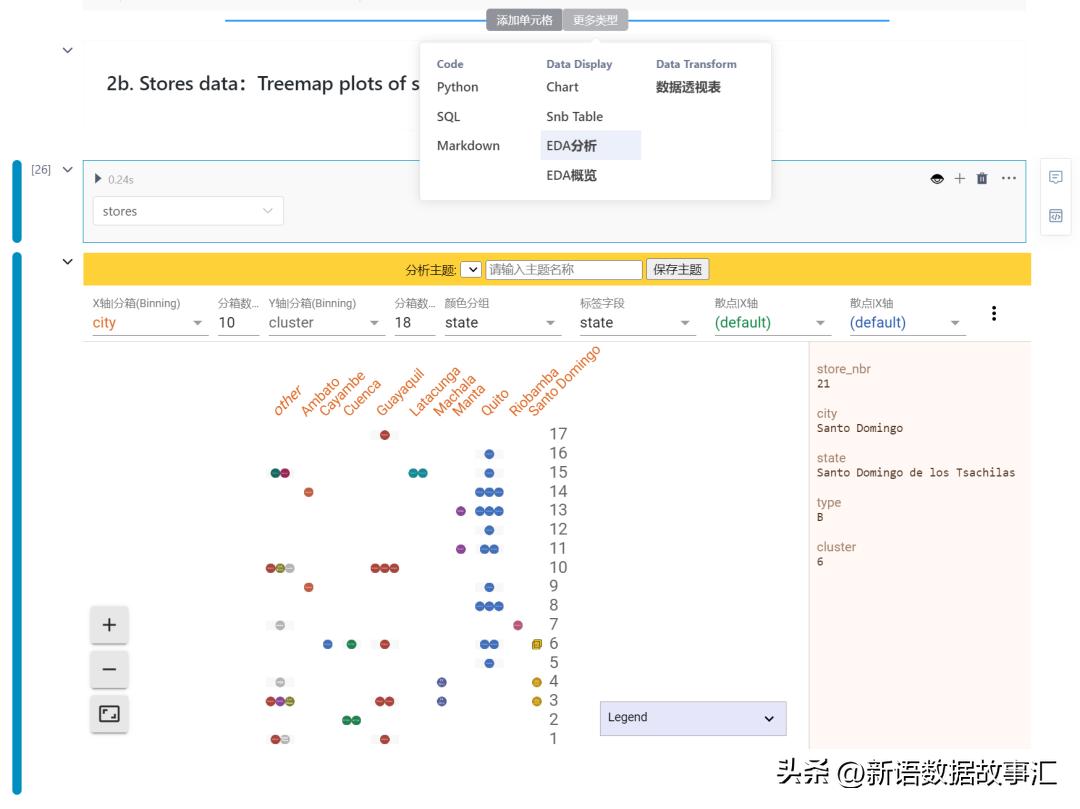
stores 店特征分布
- 选定插入EDA分析 单元格类型。
- 选定stores 数据集作为分析对象,后续自由探索和分析stores 数据集。
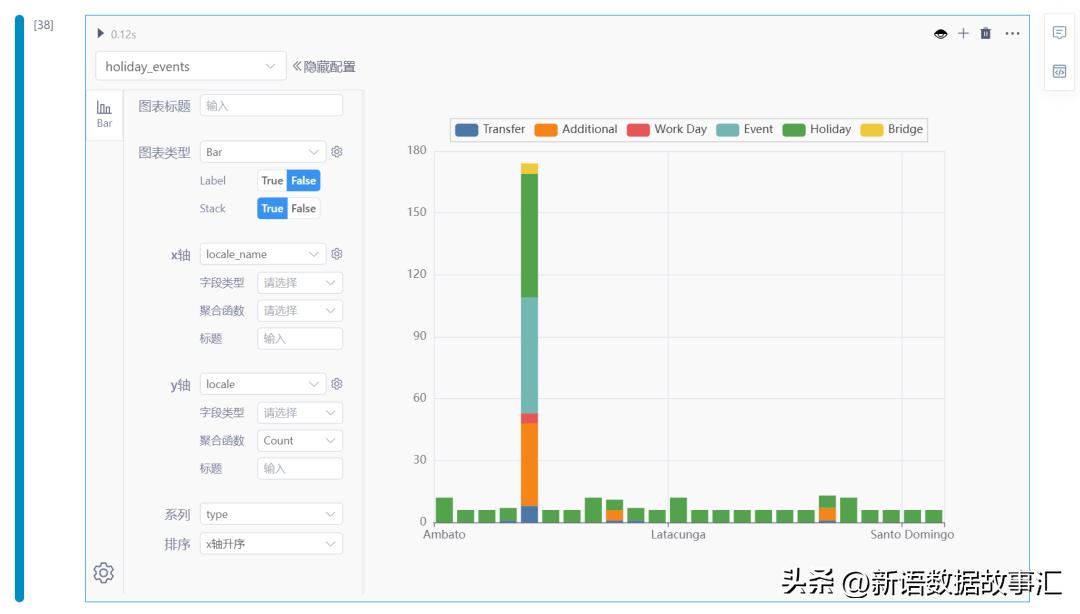
节假日数据分布
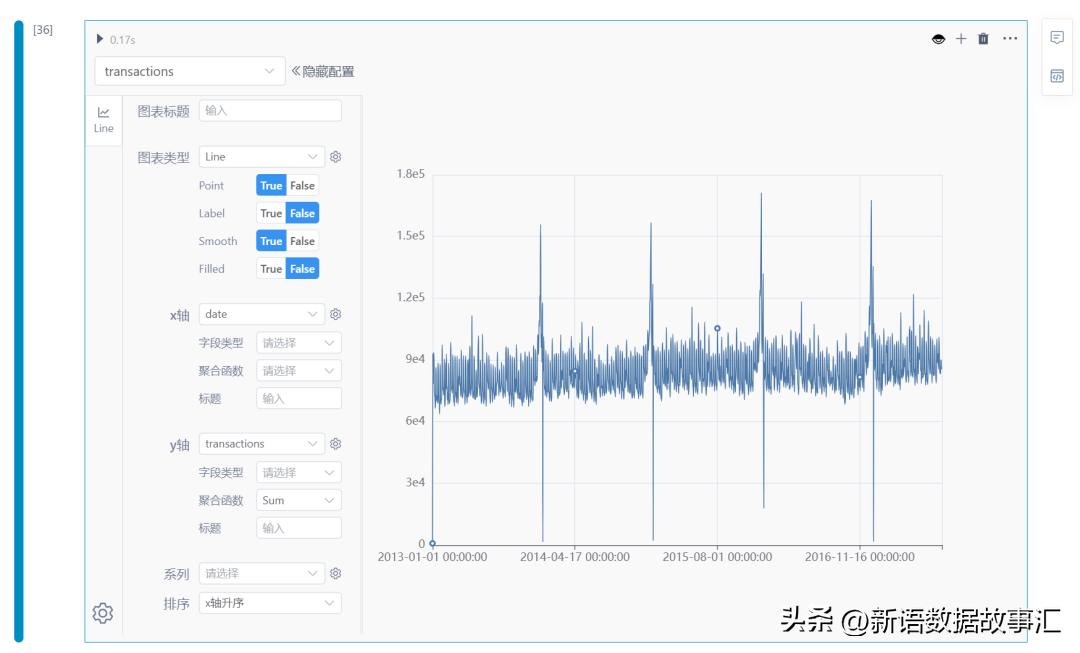
Transactions交易分析
- 周的波动周期比较稳定的。
- 节假日效果比较明显。
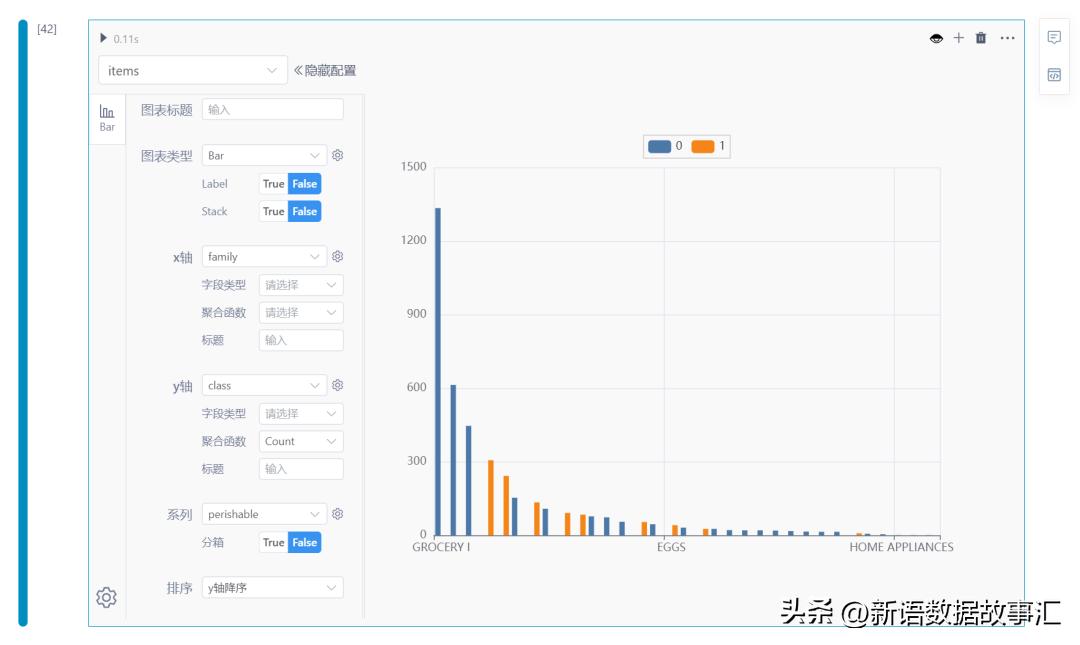
Item 商品分析
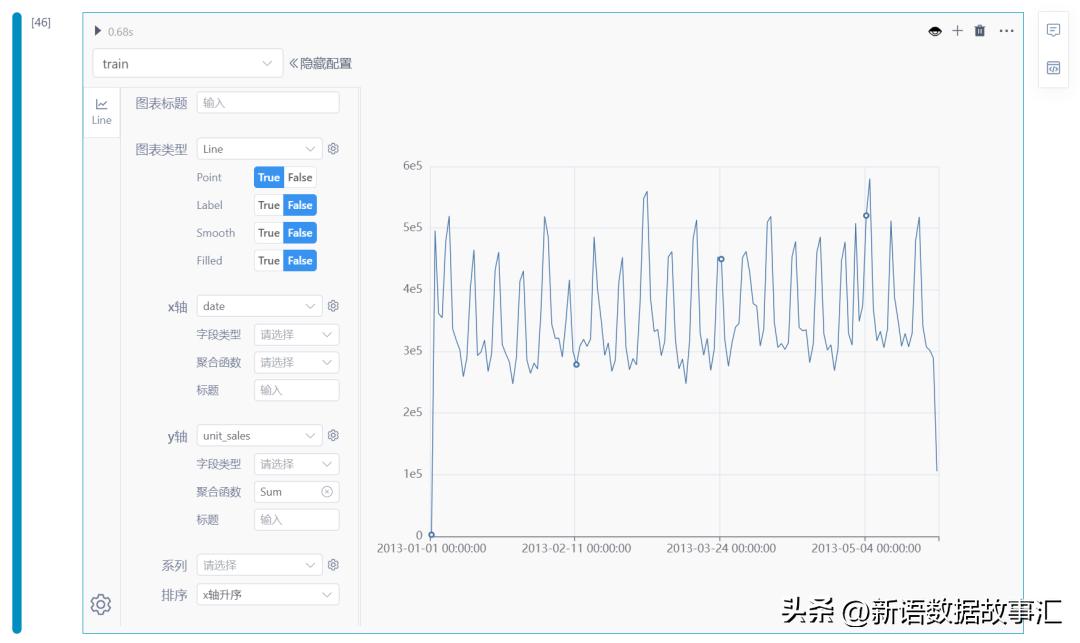
train数据统计
特征处理
接下来的部分是销量预测比较关键的部分,使用机器学习的方式进行销量预测的基本过程,是基本方式的Demo过程,中间还有很多优化的地方。
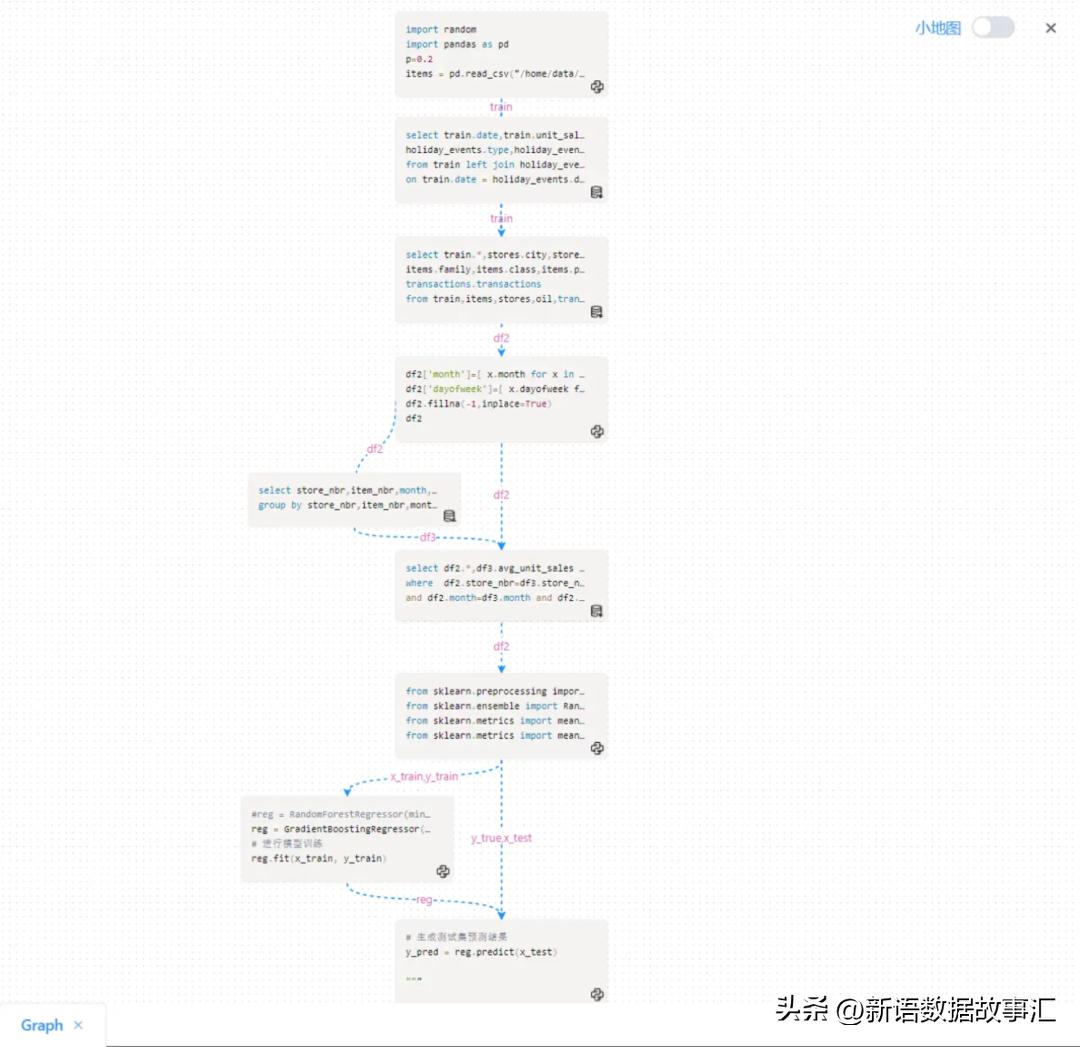
基于前面的分析,与train为主要要数据,合并Oil、stores、节假日、tansactions 数据形成宽表,同时引入时间序列特征,包括趋势、季节性和时间周期性等特征,形成为训练数据集。
- 加载数据,由于数据比较大,为过程演示方便,train 随机选取20%。
importrandom
importpandasaspd
p=0.2
items=pd.read_csv("/home/data/sales/items.csv")
holiday_events=pd.read_csv("/home/data/sales/holidays_events.csv",parse_dates=['date'])
stores=pd.read_csv("/home/data/sales/stores.csv")
oil=pd.read_csv("/home/data/sales/oil.csv",parse_dates=['date'])
transactions=pd.read_csv("/home/data/sales/transactions.csv",parse_dates=['date'])
train=pd.read_csv("/home/data/sales/train.csv",parse_dates=['date'],
skiprows=lambdai:i>0andrandom.random()>p)#nrows=6000000,
- 合并节假日(left join)、合并item、oil、store等特征信息。
selecttrain.date,train.unit_sales,train.onpromotion,train.item_nbr,train.store_nbr,
holiday_events.type,holiday_events.locale_name,holiday_events.transferred
fromtrainleftjoinholiday_events
ontrain.date=holiday_events.date
selecttrain.*,stores.city,stores.state,stores.type,stores.cluster,
items.family,items.class,items.perishable,
transactions.transactions
fromtrain,items,stores,oil,transactions
wheretrain.date=oil.date
andtrain.store_nbr=stores.store_nbrandtrain.item_nbr=items.item_nbr
andtrain.date=transactions.dateandtrain.store_nbr=transactions.store_nbr
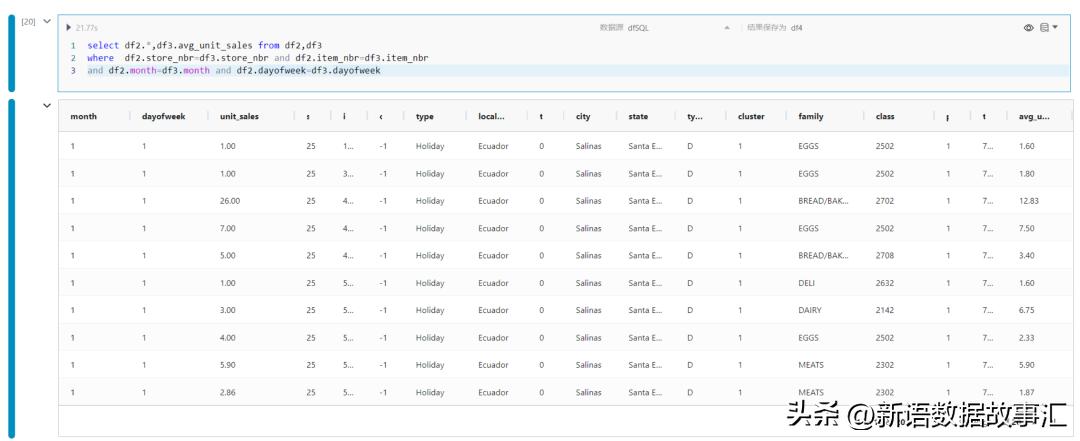
- 拆解时间特征比如:月份、dayofweek,统计历史每月、周几在每个商店单品SKU销量情况(简化处理)。
df2['month']=[x.monthforxindf2['date']]
df2['dayofweek']=[x.dayofweekforxindf2['date']]
selectstore_nbr,item_nbr,month,dayofweek,avg(unit_sales)asavg_unit_sales
fromdf2
groupbystore_nbr,item_nbr,month,dayofweek
selectdf2.*,df3.avg_unit_salesfromdf2,df3
wheredf2.store_nbr=df3.store_nbranddf2.item_nbr=df3.item_nbr
anddf2.month=df3.monthanddf2.dayofweek=df3.dayofweek
建模及评估
GradientBoostingRegressor 是一种基于梯度提升算法的回归模型。梯度提升是一种集成学习方法,通过将多个弱学习器(通常是决策树)组合起来形成一个强学习器。
GradientBoostingRegressor 的工作原理如下:它通过逐步迭代的方式训练一系列决策树模型,每一棵树都在尝试修正前一棵树的残差(预测值与实际值之间的差异)。在每一次迭代中,模型通过梯度下降的方式来最小化损失函数,使得模型的预测值与真实值之间的差异最小化。
GradientBoostingRegressor 在处理回归问题时具有较强的表现能力和泛化能力。它能够自适应地拟合数据中的非线性关系,并能够处理高维特征和具有缺失值的数据。
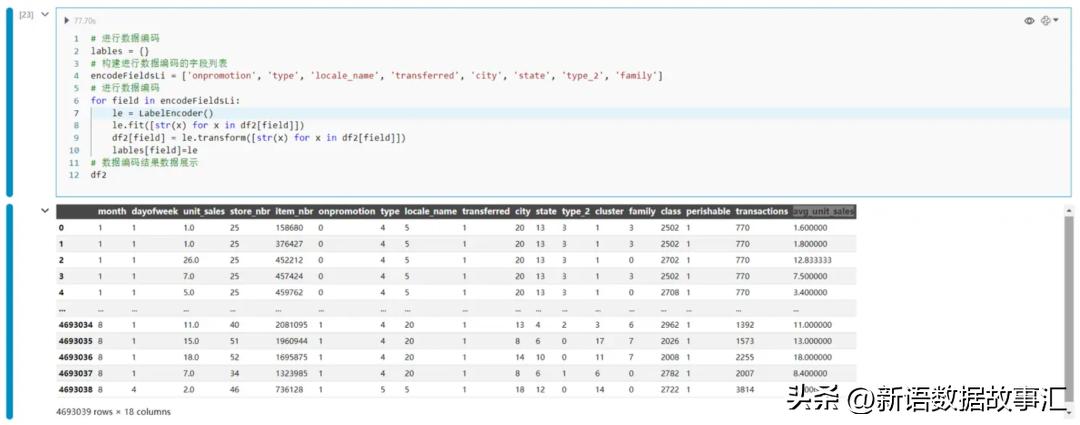
- 编码LableEncode
fromsklearn.preprocessingimportLabelEncoder
fromsklearn.ensembleimportRandomForestRegressor
fromsklearn.metricsimportmean_squared_error
fromsklearn.metricsimportmean_absolute_error
fromsklearn.metricsimportr2_score
fromsklearn.model_selectionimporttrain_test_split
fromsklearn.ensembleimportGradientBoostingRegressor
#进行数据编码
lables={}
#构建进行数据编码的字段列表
encodeFieldsLi=['onpromotion','type','locale_name','transferred','city','state','type_2','family']
#进行数据编码
forfieldinencodeFieldsLi:
le=LabelEncoder()
le.fit([str(x)forxindf2[field]])
df2[field]=le.transform([str(x)forxindf2[field]])
lables[field]=le
#数据编码结果数据展示
df2
- 设置训练模型特征变量与目标变量,拆分训练和测试数据集
#设置训练模型特征变量与目标变量
x=df2[['month','dayofweek','store_nbr','item_nbr','onpromotion','type','locale_name','transferred','city','state','type_2','cluster',
'family','class','perishable','transactions','avg_unit_sales']]
y=df2['unit_sales']
x_train,x_test,y_train,y_true=train_test_split(x,y,test_size=0.2)
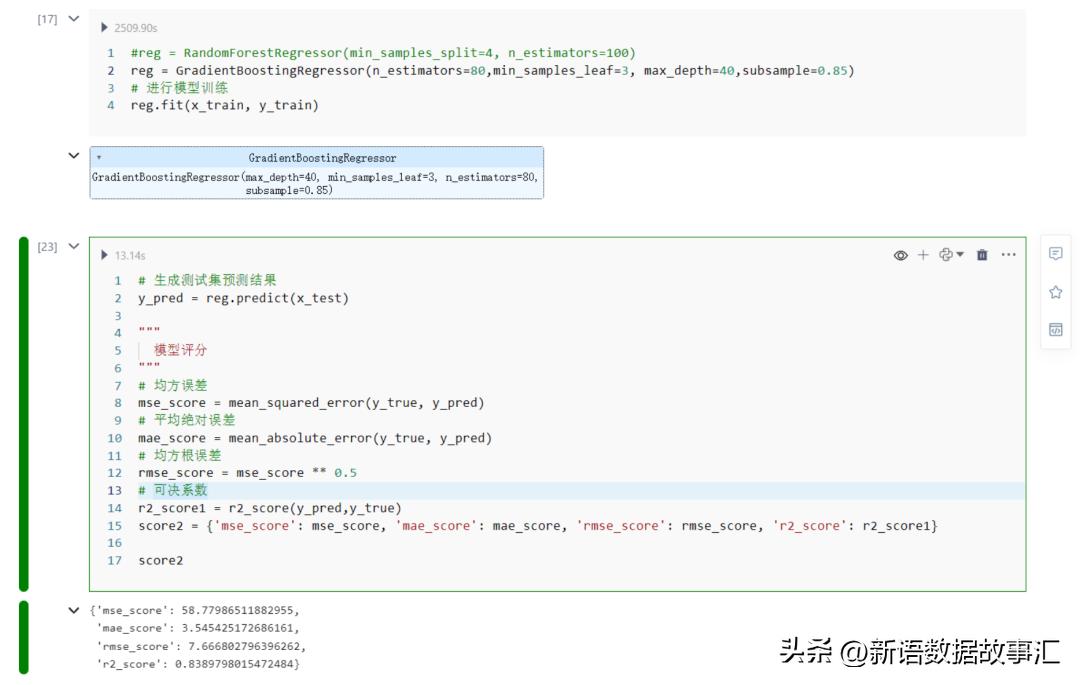
- 模型训练(GradientBoostingRegressor)
reg=GradientBoostingRegressor(n_estimators=50,min_samples_leaf=3,max_depth=40,subsample=0.90)
#进行模型训练
reg.fit(x_train,y_train)
- 测试集上评估
#生成测试集预测结果
y_pred=reg.predict(x_test)
"""
模型评分
"""
#均方误差
mse_score=mean_squared_error(y_true,y_pred)
#平均绝对误差
mae_score=mean_absolute_error(y_true,y_pred)
#均方根误差
rmse_score=mse_score**0.5
#可决系数
r2_score1=r2_score(y_true,y_pred)
score2={'mse_score':mse_score,'mae_score':mae_score,'rmse_score':rmse_score,'r2_score':r2_score1}
score2
{'mse_score':58.77986511882955,
'mae_score':3.545425172686161,
'rmse_score':7.666802796396262,
'r2_score':0.8389798015472484}
上述是利用kaggle的开放数据和SmartNoteBook进行的门店销量分析和预测模型的基本步骤,是一个预测模型的demo,没有考虑过多的细节和模型优化,还有很大提升空间,希望对大家有所借鉴。下图是模型视图(流程图):