原来以为java处理Dataframe格式的数据java像Python那样容易,真正处理的时候才知道错了,而且错得相当离谱,java自带的库里并没有处理Dataframe数据的包,这不,花了两天时间在网上找呀找,终于找到几个长得像pandas数据的包,spark,tablesaw,joinery,spark太复杂,折腾了一会放弃,tablesaw是按列处理数据的,不喜欢,放弃,只有这个joinery,简直就是pandas的翻版,太像了,而且joinery从Dataframe里取数据貌似比pandas更容易,果断决定下手,花了两天时间折腾这个joinery,还是有效果,呵呵,废话不多说,代码贴出来,供有需要的人作个参考。
一.老规矩,先建立依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/sh.joinery/joinery-dataframe -->
<dependency>
<groupId>sh.joinery</groupId>
<artifactId>joinery-dataframe</artifactId>
<version>1.10</version>
</dependency>
<!-- https://mvnrepository.com/artifact/tech.tablesaw/tablesaw-core -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
二.输入代码
package projick;
import java.io.IOException;
import java.util.Arrays;
import cn.hutool.http.HttpResponse;
import cn.hutool.http.HttpUtil;
import joinery.DataFrame;
public class opo {
public String splicingElement(String[] elements, int size,String comma) {
String ret = "";
String data_last = "";
for (int i = 0; i < size; i++) {
if(i<size-1) {
ret += elements[i] + comma;
}
else {
data_last = elements[i];
}
}
return ret + data_last;
}
public static void main(String[] args) {
String[] list_1 = {"sh600104","sh600103","sh600109","sz000158"};
HttpResponse resp00 = HttpUtil.createGet("http://qt.gtimg.cn/q=" + new opo().splicingElement(list_1,list_1.length,","))*ex.e**cute();
System.out.println("原始数据类型为:"+resp00.body().getClass().toString()); //查看数据类型。获取到的数据为字符串类型
String resp1 = resp00.body().trim(); //去掉首尾空格
System.out.println("****** 原始数据 *****");
System.out.println(resp00.body());
String resp2 = resp1.replaceAll("~", ",").replaceAll("v_sz", "").replaceAll("51,", "").replaceAll("v_sh", "").replaceAll("=", "").replaceAll("\"1", "");
String resp10 = resp2.replaceAll("\"", ",").replaceAll("\";", "n").replaceAll(";", "n");//对获取的行情数据做初步整理
String[] resp11 = resp10.split("\n"); //用split()进行分割,分割后的resp11已经是一个数组了
System.out.println("****** 初步整理后的数据 *****");
DataFrame<Object> df = new DataFrame<>();//新建DataFrame表格,()内设置字符串格式的列名,像这样("name", "value", "category")
for(int i=0;i<list_1.length;i++) {
df.append( Arrays.asList(resp11[i].split(","))); //再次分割,并按行添加数据
System.out.println(resp11[i]);
};
System.out.println("****** 最终需要获得的Dataframe格式数据 *****");
DataFrame<Object> df1 =df.drop(0); //利用drop()删除不需要的列数据,df1就是要得到的最终数据
System.out.println(df1);
System.out.println("df1的数据格式为:"+df1.getClass().toString()); //获取df1的数据格式
try {
df.writeCsv("腾讯股票实时行情数据.csv"); //保存数据
}
catch(IOException e) {
e.printStackTrace();
};
}
}
效果
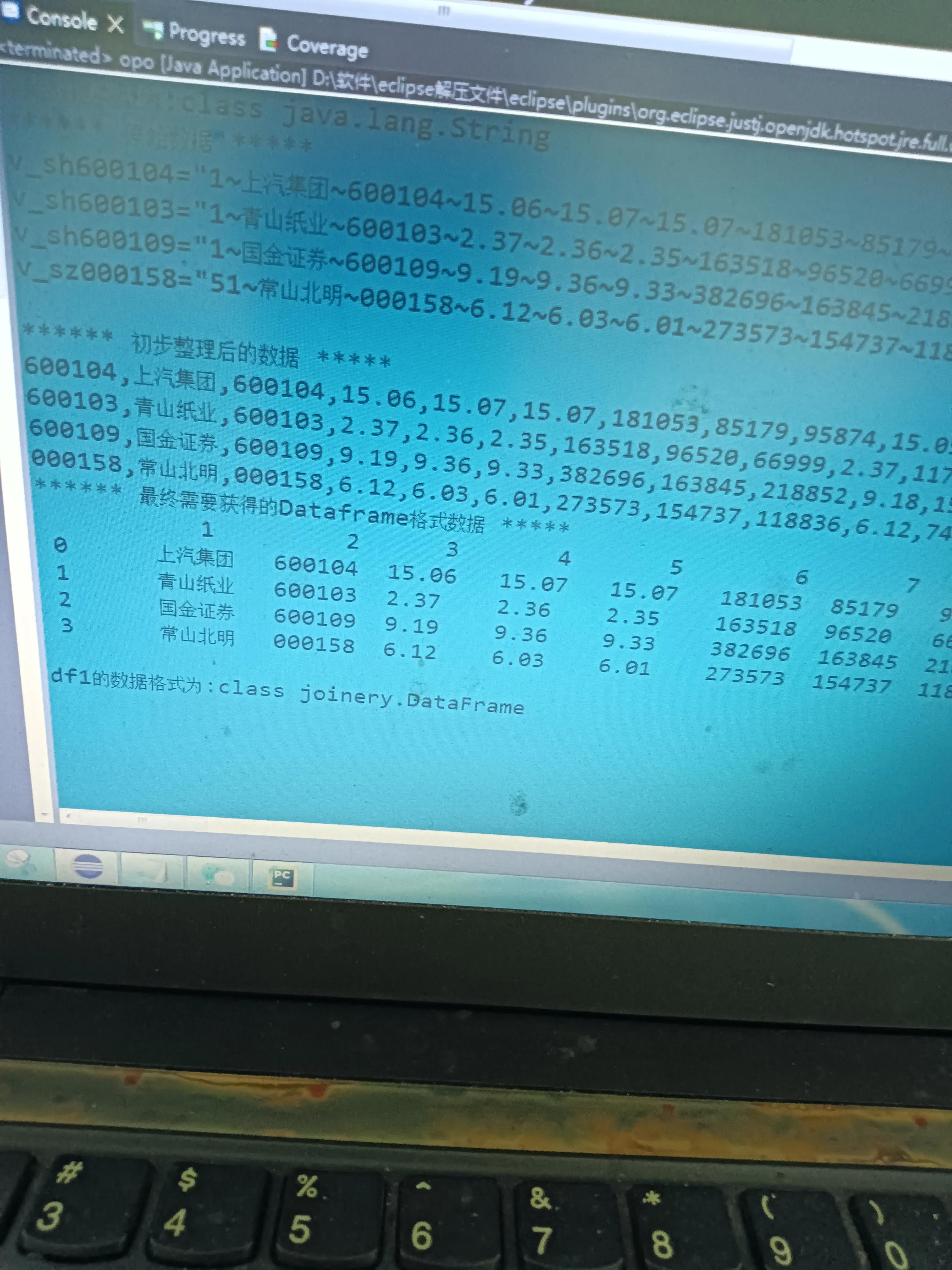
个人处理的数据可能不一样,但大体都应该差不多,程序稍加修改,照猫画虎就行了。