机器学习干货君|原创
本文内容较丰富,建议收藏后阅读
》》》文末有干货》》》

数据,没有价值
数据挖掘 使之有了意义
大数据时代,数据的意义是不可不知的。因为这至少会关系到如何正确评估我们每个行为创造出的价值,同时数据挖掘与机器学习有着极其紧密的联系。
在本文中,笔者将用简明的语言回答两个问题:
- 数据挖掘到底是什么?
- 数据挖掘具体是如何操作的?
并以此为后续的实用文章做铺垫,敬请关注头条号|机器学习干货君。
数据挖掘到底是什么?
数据挖掘是一个挖掘和分析海量数据并从中提取信息的过程。
数据在被挖掘并利用之前一直是原始文本,几乎没有意义。是数据挖掘使其有了意义。这个技术在工业和学术界的各个领域都有应用:
有了数据挖掘技术,原本在商业领域需要花费许多时间调研的问题可以被轻松快速地解决。比如:
- 市场细分
识别某类客户某一品牌的偏好
- 欺诈检测
识别可能导致欺诈的交易模式
- 等等......
简单讲完了概念,让我们来看点实在的东西:
数据挖掘是如何实现的?

数据挖掘的具体流程
以下是一个常见的数据挖掘流程:
- 第一步,数据预处理:
数据预处理是数据挖掘不可省略的必要条件。预处理包括从数据中去除异常和噪声;填充缺失值;对数据进行规范化等。

一个简单的例子是OCR的预处理
- 第二步,聚类:
聚类是将大量数据划分为相关的子类的过程,这涉及到特征提取。

数据挖掘软件Weka被用于特征选择
- 最后,分类:
在这一步中,数据被标记上用户定义的类别,比如图像识别问题中的“车”,“人”,“动物”等。

除以上主要的三步以外,还有一些重要的技巧:
- 异常值分析:
异常值分析有助于识别那些偏离或远离数据集中其他元素的数据元素,用于异常检测。
常见的方法有:
- 奈尔(Nair)检验法(仅用于标准差已知的情形)
- 格拉布斯(Grubbs)检验法
- 狄克逊(Dixon)检验法
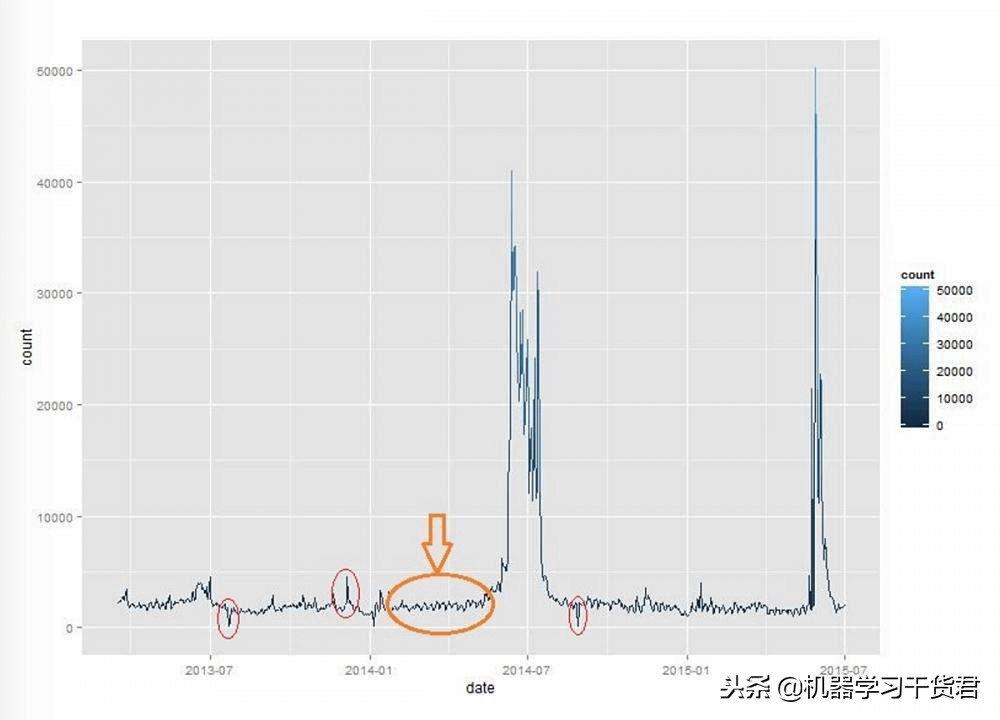
异常检测的一个例子
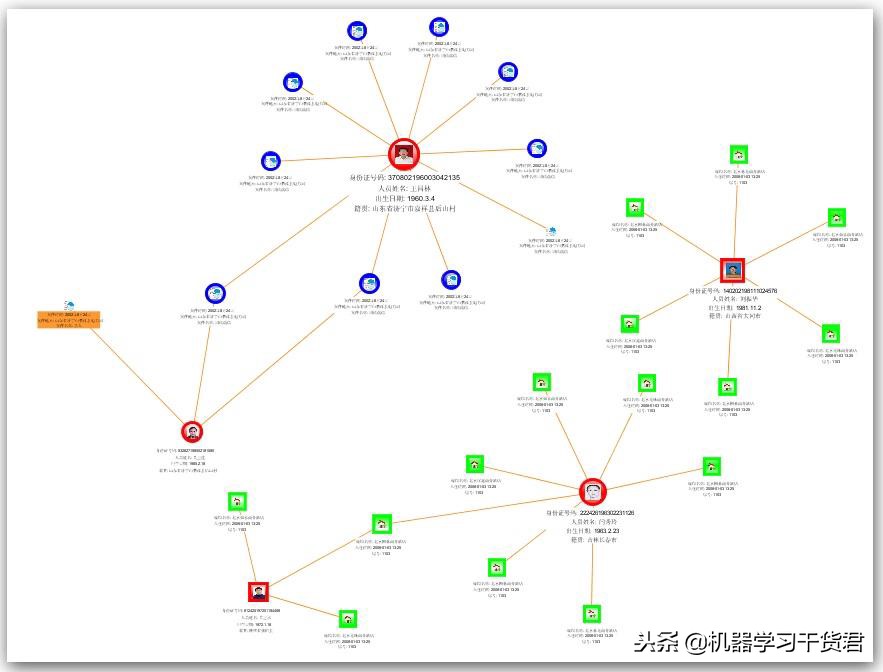
- 关联分析:
关联分析有助于在大型数据集中的数据项之间建立隐藏的关系。这有助于在存在某一项时预测其他项是否会发生。
- 数据回归:
回归是通过构造一个模型或一个数学函数来预测因变量与自变量的关系。相信数据回归大家已经很熟悉了,毕竟机器学习的主要应用就是实现数据回归。对数据回归感兴趣的读者可以参考笔者以往的干货文章干货|机器学习5大关键算法深入盘点!一个比一个艰深。
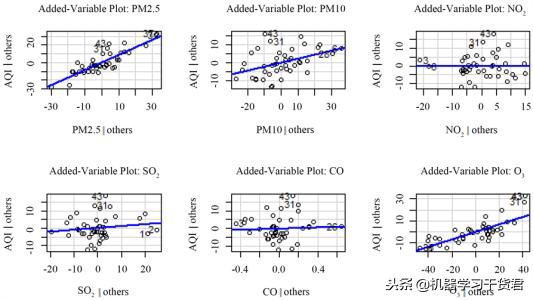
数据回归的一个例子(线性回归)
结语
数据挖掘是模式识别、统计、机器学习等各种技术的组合。机器学习和数据挖掘之间有很大的交集, 因为两者都是齐头并进的。
可以说:我们学习数据挖掘,就是为机器学习服务的。同时学好了机器学习反过来也能提升数据挖掘的能力。
相关干货:
想要系统地学好机器学习吗?这里有一份精品课程资源等你领取!

请先点击关注;然后私信发送“顶级大学资源”
即可领取一份笔者精心整理的机器学习课程资源(中文字幕)
机器学习干货君致力于原创易于理解的技术原理与细节文章
I Studied Hard,
So YOU Don't Have To !
欢迎大家关注: )